前言
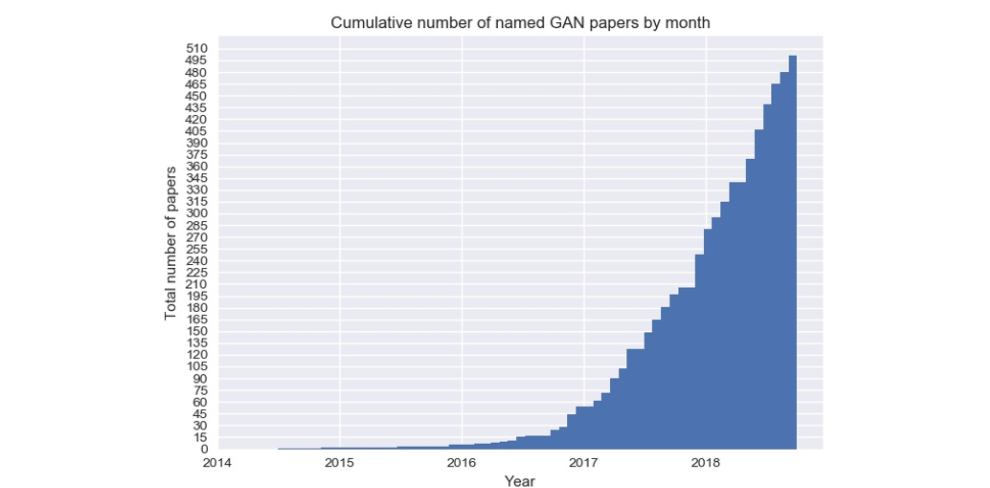
GAN的全称为Generative Adversarial Network,翻译成中文就是生成式对抗网络。 在github有个GAN Zoo,它记录了GAN的发展并提供了相关GAN的论文来源和部分GAN模型的实现。下图为GAN的论文数量随时间的变化,由图可以看出自2014年第一篇GAN的论文问世,GAN的数量就以指数增长形式迅速壮大。虽然GAN的种类千变万化,但它们的结构类似,都含有一个生成器(generator)和一个判别器(discriminator)。
判别器和生成器都是一个神经网络结构,也就是一个黑箱模型。判别器相对比较好理解,就像一个二分类模型,有一个判别界限去区分样本,从概率的角度分析就是获得样本x属于类别y的概率,是一个条件概率P(y|x)。而生成器是需要生成数据的概率分布,就像高斯分布一样,需要去拟合整个分布,从概率角度分析就是样本x在整个分布中对应的概率。
GAN的相关理论
GAN本质上是在做什么事情呢?
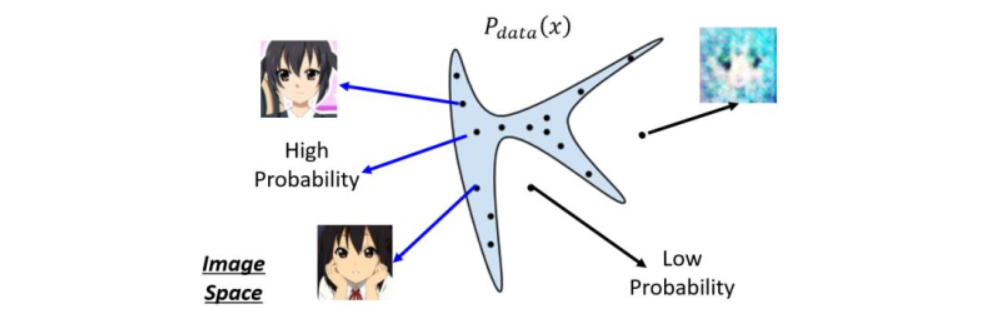
以图像生成为例,我们假设吧每一个图片看作二维空间中的一个点,并且现有图片会满足于某个数据分布,我们记作$P_{data}(x)$。那么在这个图像分布空间中,实际上只有很小一部分的区域是人脸图像。如上图所示,只有在蓝色区域采样出的点才会看起来像人脸,而在蓝色区域外采样出来的点就不是人脸。而在GAN中我们需要做的就是让机器找到人脸的分布函数,这也是GAN本质上做的事情。
Generator
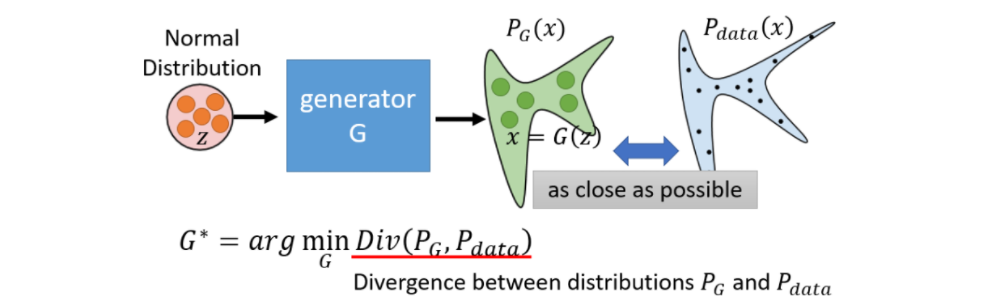
如下图所示,我们需要训练出这样一个生成器,对于一个已知分布的数据z,我们可以通过生成器把数据转化成一个高维向量,它可以表示为一个图片、文本、声音等。只要我们随机输入多个z,就可以生成一个关于数据x的分布,我们把它称作$P_{G}(x)$。而真实数据也对应一个分布$P_{data}(x)$,生成器的目标是使$P_{G}(x)$和$P_{data}(x)$这两个分布越相似越好。我们知道对于回归和分类模型,都有对应的目标函数,我们只需使这个目标函数达到最优,即可得出一个比较好的回归或分类模型。那么对于两个分布,我们可以利用散度(Divergence,简称Div)这个评价指标来衡量两个分布之间的相似性。Div越小就表示两个分布越相似。那么我们可以将Div作为训练G的目标函数,我们的目标是使Div最小。
Discriminator
现在有一个最关键的问题是,两个分布之间的Div要如何计算出来呢?理论上来说我们不知道$P_{G}(x)$和$P_{data}(x)$是什么,因此Div我们是无法计算的。因此我们需要构建一个新的网络,它的作用是衡量$P_{G}(x)$和$P_{data}(x)$之间的Div,因此我们有了这样一个网络——判别器。
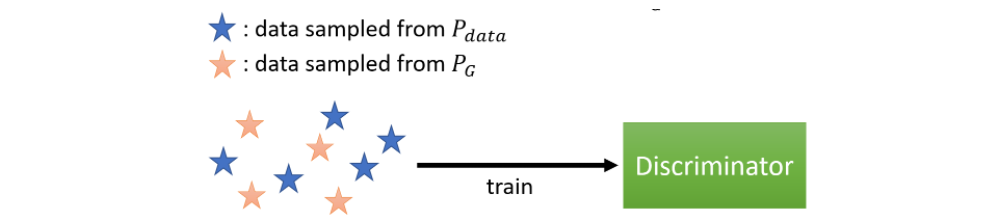
图中,蓝色星星是从$P_{data}$(真实数据)中采样出的数据,黄色星星是从$P_{G}$(生成的数据)中采样出的数据,现在我们将这两组数据交给判别器,判别器的功能是判别读入的数据是来自$P_{data}$还是$P_{G}$。如果输入数据是$P_{data}$,那么经过判别器后就输出一个较大的值(可以近似理解为输出1)。如果输入数据是$P_{G}$,那么经过判别器后就输出一个较小的值(可以近似理解为输出0)。熟悉分类模型的同学可能就会说判别器不就相当于是一个二分类模型吗?而前面不是说我们是以Div的大小来判断两个分布之间的相似程度。现在我们就用公式推导出Div和二分类模型的目标函数之间的相关性。
我们先来看一下判别器的目标函数:

从式子本身理解的话,数据来源于$P_{data}$,D(x)要尽可能大,数据来源于$P_{G}$,D(x)要尽可能小。这样的话$V(G,D)$就越大。以最大化$V(G,D)$为目标函数,就可以使得输入数据是$P_{G}$,经过判别器后就输出一个较小的值,相反则输入一个较大的值。这样就达到了区分读入的数据是来自$P_{data}$还是$P_{G}$的目的。接下来我们将目标函数展开:

假设判别器十分强大,它模拟出的D(x)可以表示任何函数,给定一个x,都有一个D(x)使得表达式$P_{data}(x)logD(x)+P_{G}(x)log(1-D(x))$最大,求导令其为0可以得出:
$$D^{}(x)=\frac{P_{data}(x)}{P_{data}(x)+P_{G}(x)}$$
现在把$D^{}(x)$带入到目标函数中得到:
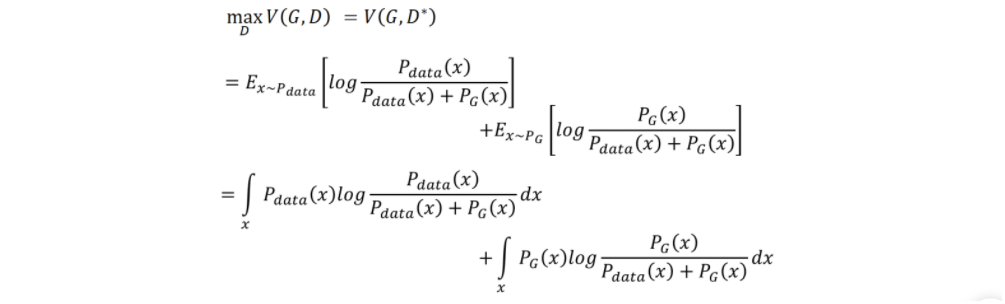
将表达式中分子分母都除于2可得:
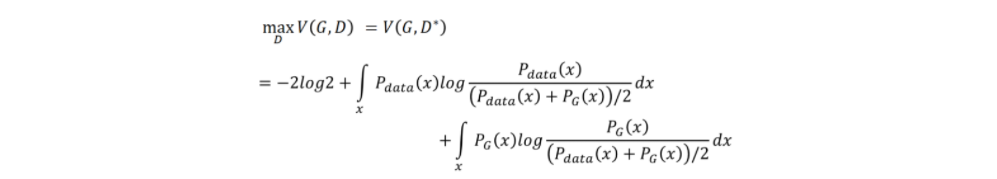
这个表达式等价为:

至此我们可以得知通过一定的假设,得出散度的计算类似于二分类器的目标函数的计算。因此可以看出判别器的本质就是一个二分类器,这样就有利于我们后面代码的实现。
现在我们再回到生成器,生成器的目的是让生成数据$P_{G}$和真实数据$P_{data}$之间的Div最小,本来Div是没办法计算的,但是现在有了判别器之后,Div变得可以计算了,于是生成器新的目标函数变为:
$$G^{*}=arg\underset{G}{min}\underset{D}{V(G,D)}$$
至此,GAN就变成了一个求解最小最大值的问题,接下来就可以用最基本的梯度下降法求解这个问题。
下面我们用一个完整的伪算法来回顾一下GAN模型训练的整个流程。

这段伪代码的意思是,首先我们初始化生成器和判别器的参数,接下来规定一个总迭代次数,每轮训练的迭代次数也确定(这个根据数据量大小确定,一般是3-5次为一轮),在每轮训练中,我们先训练判别器,先从真实数据分布$P_{data}(x)$中抽样x,然后从先验分布中抽样z,并通过生成器产生数据$\overset{-}{x}$,接着把x和$\overset{-}{x}$丢入判别器中训练,使得目标函数$\overset{-}{V}$最大;接下来我们训练生成器,从先验分布中抽样新的z,接下来把z丢进生成器中训练,使得目标函数$\overset{-}{V}$最小,其实这一步就是让这一轮训练好的判别器认为生成器生成的是真实的数据。这样循环交替,最终生成器产生的数据$\overset{-}{x}$就会越来越接近真实数据x。
参考资料
[2] 李宏毅youtube课程



