假设某个序列我们可以使用$x_{t-1},…,x_{t-\tau}$而不是$x_{t-1},…,x_{1}$来估计$x_{t}$,我们就说该序列满足马尔可夫条件。用数学公式表示为:
$$P(x_{1},…,x_{T})=\underset{t=1}{\overset{T}{\Pi}}P(x_{t}|x_{t-1},…,x_{t-\tau})$$
而$\tau=1$,我们就得到一个一阶马尔可夫模型,则上式变为:
$$P(x_{1},…,x_{T})=\underset{t=1}{\overset{T}{\Pi}}P(x_{t}|x_{t-1})$$
利用这一事实,我们只需要考虑过去观察中的一个非常短的历史:$P(x_{t}|x_{t-1},…,x_{1})=P(x_{t}|x_{t-1})$就能近似得出当前状态。
现在我们做一个简单的实验,来探讨一下满足马尔可夫条件的模型预测的准确性,以及它的最大预测能力。
生成数据
首先,我们生成一些数据:使用正弦函数和一些可加性噪声来生成序列模型,时间步长为1000。
import torch
T = 1000 # 总共产生1000个点
time_epoch = torch.arange(1, T + 1)
y = torch.sin(0.01 * time_epoch) + torch.normal(0, 0.2, (T,))绘制图片
import matplotlib.pyplot as plt
plt.plot(time_epoch, y)
plt.xlabel('time_epoch')
plt.ylabel('y')
plt.xlim([1, 1000])
数据预处理
接下来我们对序列进行一定的处理,使这个序列转换为模型的“特征-标签”对,这里我们使用的$\tau=4$,由于前4个数据没有历史数据来描述它们,因此我们将其舍去。
from torch.utils.data import DataLoader, Dataset
class DigitDataset(Dataset):
def __init__(self, x, y):
self.x = x
self.y = y
def __len__(self):
return len(self.x)
def __getitem__(self, idx):
X = self.x[idx]
Y = self.y[idx]
return X, Y
tau = 4
features = torch.zeros((T - tau, tau))
for i in range(tau):
features[:, i] = y[i: T - tau + i]
labels = y[tau:].reshape(-1, 1)
# print(features.shape, labels.shape)
batch_size, n_train = 16, 600 # 仅使用前600个数据进行模型训练
train_set = DigitDataset(features[: n_train], labels[: n_train])
dataloader = DataLoader(train_set, batch_size=batch_size)构建模型
在这里我们构建一个十分简单的网络来训练模型:一个拥有两个全连接层的多层感知机,ReLU激活函数,
import torch.nn as nn
# 初始化网络权重参数
def init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.net = nn.Sequential(
nn.Linear(4, 10),
nn.ReLU(),
nn.Linear(10, 1),
)
self.apply(init_weights)
def forward(self, x):
y = self.net(x)
return y训练
设置超参数以及optimizer, criterion,并进行训练
# 模型
model = MLP()
model.train()
n_epoch = 10
lr = 0.01
# optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# criterion
criterion = nn.MSELoss()
# Training
for epoch in range(n_epoch):
total_loss = 0
for i,data in enumerate(dataloader):
# 前向传播
y_pred = model(data[0])
# 后向传播
loss = criterion(y_pred, data[1])
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss * len(data)
# 结果展示
print(f'Epoch [{epoch + 1}/{n_epoch:02d}] Loss: {total_loss / n_train}')Epoch [1/10] Loss: 0.054475486278533936
Epoch [2/10] Loss: 0.015365694649517536
Epoch [3/10] Loss: 0.011502934619784355
Epoch [4/10] Loss: 0.006994950119405985
Epoch [5/10] Loss: 0.007959885522723198
Epoch [6/10] Loss: 0.008115933276712894
Epoch [7/10] Loss: 0.009392841719090939
Epoch [8/10] Loss: 0.008084502071142197
Epoch [9/10] Loss: 0.0074587250128388405
Epoch [10/10] Loss: 0.006592489313334227
预测
由训练误差可知,模型运行的效果不错,现在让我们检验模型的预测能力,首先检验模型预测下一个时间步的能力
onestep_preds = model(features)
plt.plot(time_epoch, y)
plt.plot(time_epoch[tau:], onestep_preds.detach().numpy(), color = 'r')
plt.xlabel('time_epoch')
plt.ylabel('y')
plt.xlim([1,1000])
plt.legend(['data', '1-step preds'])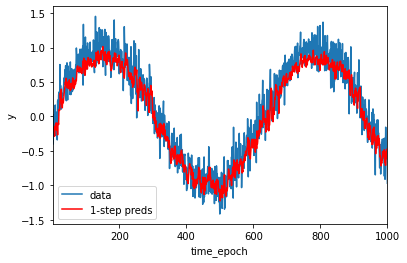
由图可以看出。单步预测效果不错。即使预测的时间步超过了600+4(n_train + tau),其预测结果看起来仍然不错。但如果数据观察序列只到了604,后面的都需要我们进行预测,那么这个模型的结果将会成为什么样子?还会有这么好的预测效果吗?
multistep_preds = torch.zeros(T)
multistep_preds[: n_train + tau] = y[: n_train + tau]
for i in range(n_train + tau, T):
multistep_preds[i] = model(multistep_preds[i - tau: i]).reshape(1, -1)
# 绘图
plt.plot(time_epoch, y)
plt.plot(time_epoch[tau:], onestep_preds.detach().numpy())
plt.plot(time_epoch, multistep_preds.detach().numpy())
plt.xlabel('time_epoch')
plt.ylabel('y')
plt.xlim([1,1000])
plt.legend(['data', '1-step preds', 'multistep preds'])
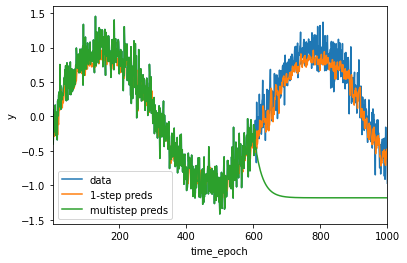
由图可以看出绿线的预测显然不是很理想,经过几个预测步骤之后,预测的结果很快就会衰减到一个常数。这其实是错误累积的结果,因此后面误差会相当快地偏离真实的观测结果。
现在我们将预测步数分别设置为1,4,16,64,通过对比比较,看看k步预测的困难。
max_steps = 64
features = torch.zeros((T - tau - max_steps + 1, tau + max_steps))
# 列i(i<tau)是来⾃x的观测,其时间步从(i+1)到(i+T-tau-max_steps+1)
for i in range(tau):
features[:, i] = y[i : T - tau -max_steps + 1 + i]
# 列i(i>=tau)是来⾃(i-tau+1)步的预测,其时间步从(i+1)到(i+T-tau-max_steps+1)
for i in range(tau, tau + max_steps):
features[:, i] = model(features[:, i - tau:i]).reshape(-1)
steps = (1, 4, 16, 64)
# 绘图
for i in steps:
plt.plot(time_epoch[tau + i -1: T - max_steps + i] , features[:, tau + i - 1].detach().numpy())
plt.xlabel('time_epoch')
plt.ylabel('y')
plt.xlim([5,1000])
plt.legend([f'{i}-step preds' for i in steps])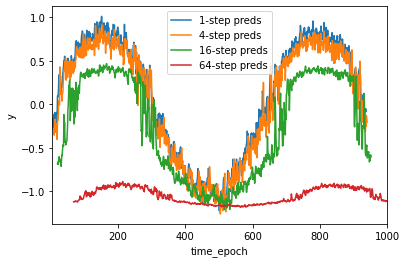
以上例子清楚地说明随着预测步数的增加,预测的结果逐渐变坏。虽然“4步预测”看起来仍然不错,但超过这个跨度的任何预测几乎都是无用的。



