LSTM
长短期记忆神经网路(long short-term memory,LSTM)是一种RNN特殊类型,现在我们见到的RNN模型除了特别强调,一般都是LSTM。LSTM的设计灵感来源于计算机的逻辑门,它引入了记忆元(memory cell),记忆元的作用是用于记录附加的信息。为了控制记忆元,我们需要许多门。其中一个门用来从单元中输出条目,我们将其称为输出门(output gate)。另一个门用来决定何时将数据读入单元,我们将其称为输入门(input gate)。我们还需要一个门来决定什么时候记忆或忽略隐状态中的输入,我们将其称为遗忘门(forget gate)。除此之外还有一个候选记忆元(candidate memory cell),它用来控制输入门的状态。现在让我们看看这在实践中是怎么运作的。
LSTM当前时间步的输⼊和前⼀个时间步的隐状态作为数据送⼊⻓短期记忆⽹络的⻔中,它们由三个具有sigmiod激活函数的全连接层处理,以计算输入门、输出门和遗忘门的值。候选记忆元的结构与前面三个门相似,只是使用tanh函数来作为激活函数。
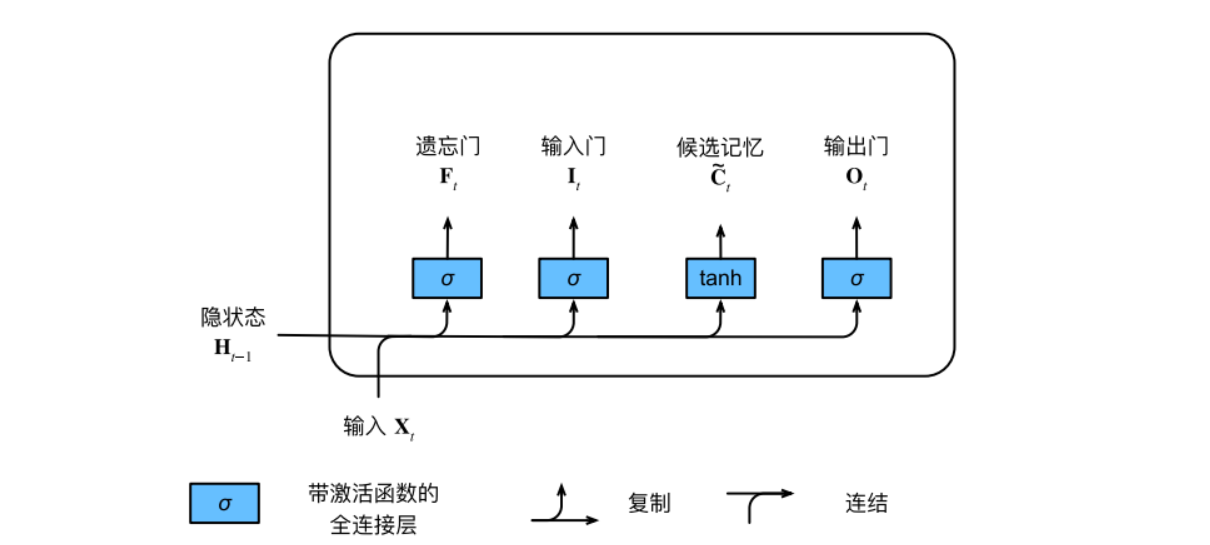
现在我们来细化一下长短期记忆网络的数学表达。假设输入为$X_{t}\in R^{nxd}$,隐藏单元的个数是h,则前一时间步的隐状态为$H_{t-1}\in R^{nxh}$。相应地,输入门是$I_{t}\in R^{nxh}$,遗忘门是$F_{t}\in R^{nxh}$,输出们是$O_{t}\in R^{nxh}$,候选记忆元是$\overset{-}{C_{t}}\in R^{nxh}$。它们的计算方法如下:
$$I_{t}=\sigma(X_{t}W_{xi}+H_{t-1}W_{hi}+b_{i}),$$
$$F_{t}=\sigma(X_{t}W_{xf}+H_{t-1}W_{hf}+b_{f}),$$
$$O_{t}=\sigma(X_{t}W_{xo}+H_{t-1}W_{ho}+b_{o}),$$
$$\overset{-}{C_{t}}=tanh(X_{t}W_{xc}+H_{t-1}W_{hc}+b_{c}),$$
式中$W_{xi},W_{xf},W_{xo},W_{xc}\in R^{dxh}$和$W_{hi},W_{hf},W_{ho},W_{hc}\in R^{hxh}$是权重参数,$b_{i},b_{f},b_{o},b_{c}\in R^{1xh}$是偏置参数。
在LSTM中,有两个来控制输入或遗忘:输入门$I_{t}$控制采用多少来自$\overset{-}{C_{t}}$的新数据,而遗忘门$F_{t}$控制保留多少过去的记忆元$C_{t-1}\in R^{nxh}$的内容。它们之间使用Hadamard积,有:
$$C_{t}=F_{t}\bigodot C_{t-1}+I_{t}\bigodot \overset{-}{C_{t}}$$
如果遗忘⻔始终为1且输⼊⻔始终为0,则过去的记忆元$C_{t}$将随时间被保存并传递到当前时间步。引⼊这种设计是为了缓解梯度消失问题,并更好地捕获序列中的⻓距离依赖关系。
现在,我们还需要定义如何计算隐状态$H_{t}\in R_{nxh}$,这就是输出门发挥作用的地方。在LSTM中,它将记忆元经过tanh激活函数,并于输出之间做Hadamard积:
$$H_{t}=O_{t}\bigodot tanh(C_{t})$$
这样我们就得到LSTM一个神经元完整的内部结构:
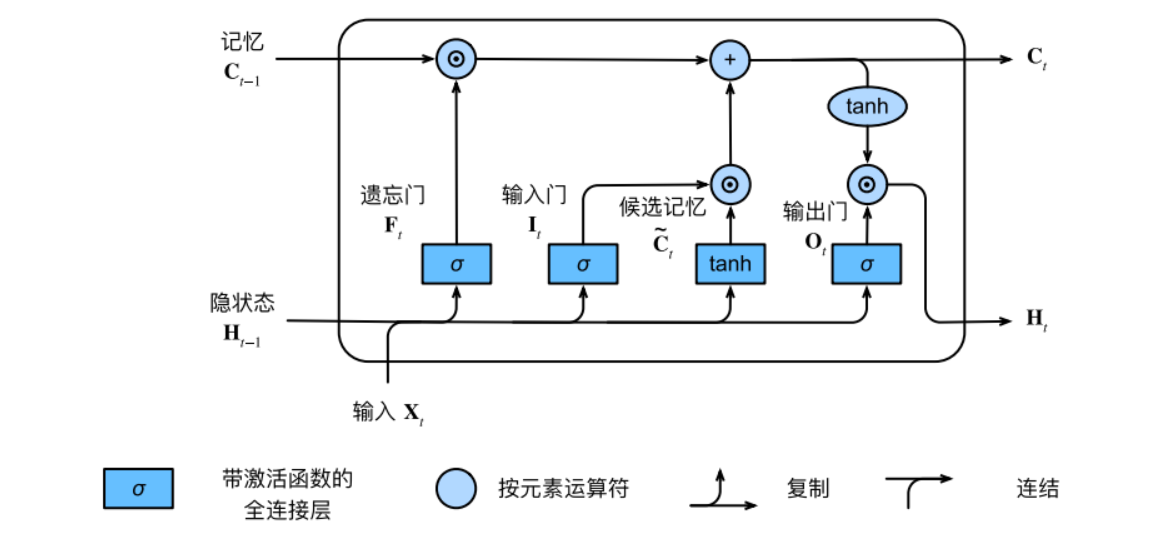
最后只需将最新的隐状态作为输入经过另一个网络,则可实现分类或回归等模型。
这只是LSTM单个神经元的内部结构,而事实上LSTM可以将多层网络结构堆叠在一起,每层网络结构含有多个神经元结构。通过对几个层进行组合,我们就可以产生一个灵活的网络结构。
LSTM应用
现在我们以一个新闻标题分类的例子来实现LSTM,本次实验应用的是清华NLP组提供的THUCNews文本分类数据集,它包含十个新闻主题,分别是财经、房产、股票、教育、科技、社会、时政、体育、游戏。训练集中总共有180000条数据,每个类别有200000条数据。验证集中总共有10000条数据,每个类别有1000条数据。
分词及去除停用词
由于训练数据是中文,因此需要对文本进行分词处理,分词采用的是python中的jieba工具。同时为了减少停用词对文本有效信息造成噪音干扰,减少模型复杂程度,我们对文本进行去除停用词处理。
import jieba
import os
import re
# 数据所在路径
data_dir = 'E:\软件包\Chrome\机器学习数据\THUCNews'
# 停用词表对应路径
stopwords_path = os.path.join(data_dir, '中文停用词库.txt')
# 将停用词转换为python列表
stopwords_list = [line.strip() for line in open(stopwords_path, 'r', encoding='gbk').readlines()]
# 定义一个函数,用于对文本分词和去除停用词处理
def text_preprocessing(text):
# 去除文本额外信息
text = text.replace('(图)', '')
# 只保留数字、字母、中文
text = re.sub(r'[^a-zA-Z0-9\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]', ' ', text)
# 分词
words = jieba.cut(text)
text_list = [word.strip() for word in words if word not in stopwords_list and len(word.strip()) > 1]
return text_list
def load_data(path):
# 把 training 时需要的资料读进来
f = open(path, 'r', encoding='utf-8')
lines = f.readlines()
lines = [line.strip().split('\t') for line in lines]
x = [text_preprocessing(line[0]) for line in lines]
y = [int(line[1]) for line in lines]
return x, yword embedding
这里采用的时gensim中word2vec的skip-gram,相关使用请看官网,关于Gensim 4.0的相关更新请看这里
from gensim.models import word2vec
def train_word2vec(x):
# 训练 word to vector 的 word embedding
model = word2vec.Word2Vec(x, vector_size=250, window=5, min_count=5, epochs=10, sg=1)
return model
if __name__ == "__main__":
print("loading training data ...")
train_x, train_y = load_data(os.path.join(data_dir, 'train.txt'))
print("loading testing data ...")
test_x, test_y = load_data(os.path.join(data_dir, 'test.txt'))
# model
model = train_word2vec(train_x + test_x)
print("saving model ...")
save_path = './logs/w2v.model'
model.save(save_path)loading training data ...
loading testing data ...
saving model ...
数据预处理
import torch
import torch.nn as nn
class Preprocess():
def __init__(self, sentences, sen_len, w2v_path='w2v.model'):
self.w2v_path = w2v_path
self.sentences = sentences
self.sen_len = sen_len
self.idx2word = []
self.word2idx = {}
self.embedding_matrix = []
def get_w2v_model(self):
# 把之前训练好的 word to vector 模型读进来
self.embedding = word2vec.Word2Vec.load(self.w2v_path)
self.embedding_dim = self.embedding.vector_size
def add_embedding(self, word):
# 把 word 加进 embedding,并赋予它一个随机生成的具有代表性的 vector
# word 只会是 "<PAD>" 或 "<UNK>"
vector = torch.empty(1, self.embedding_dim)
torch.nn.init.uniform_(vector)
self.word2idx[word] = len(self.word2idx)
self.idx2word.append(word)
self.embedding_matrix = torch.cat([self.embedding_matrix, vector], 0)
def make_embedding(self, load=True):
print("Get embedding ...")
# 取出训练好的 Word2vec word embedding
if load:
print("loading word to vec model ...")
self.get_w2v_model()
else:
raise NotImplementedError
# 制作一个 word2idx 的 dictionary
# 制作一个 idx2word 的 list
# 制作一个 word2vector 的 list
for i, word in enumerate(self.embedding.wv.key_to_index):
self.word2idx[word] = len(self.word2idx)
self.idx2word.append(word)
self.embedding_matrix.append(self.embedding.wv.get_vector(word))
self.embedding_matrix = torch.tensor(self.embedding_matrix)
# 将 "<PAD>" 跟 "<UNK>" 加进 embedding 里面
self.add_embedding("<PAD>")
self.add_embedding("<UNK>")
print("total words: {}".format(len(self.embedding_matrix)))
return self.embedding_matrix
def pad_sequence(self, sentence):
# 将每个句子变成一样的长度
if len(sentence) > self.sen_len:
sentence = sentence[:self.sen_len]
else:
pad_len = self.sen_len - len(sentence)
for _ in range(pad_len):
sentence.append(self.word2idx["<PAD>"])
assert len(sentence) == self.sen_len
return sentence
def sentence_word2idx(self):
# 把句子里面的字转成对应的 index
sentence_list = []
for i, sen in enumerate(self.sentences):
sentence_idx = []
for word in sen:
if (word in self.idx2word):
sentence_idx.append(self.word2idx[word])
else:
sentence_idx.append(self.word2idx["<UNK>"])
# 将每个句子变成一样的长度
sentence_idx = self.pad_sequence(sentence_idx)
sentence_list.append(sentence_idx)
return sentence_list模型
import torch
import torch.nn as nn
class LSTM_Net(nn.Module):
def __init__(self, embedding, embedding_dim, hidden_dim, num_layers, num_classes, dropout=0.5, fix_embedding=True):
"""
embedding: 词典
embedding_dim: 词向量的维度
hidden_dim: GRU神经元个数
num_layers: GRU的层数
output_dim: 隐藏层输出的维度(分类的数量)
"""
super(LSTM_Net, self).__init__()
# 制作 embedding layer
self.embedding = torch.nn.Embedding(embedding.size(0), embedding.size(1))
self.embedding.weight = torch.nn.Parameter(embedding)
# 如果 fix_embedding 为 False,在训练过程中,embedding 也会跟着被训练
self.embedding.weight.requires_grad = False if fix_embedding else True
self.embedding_dim = embedding.size(1)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, num_layers=num_layers, bidirectional=True, batch_first=True, dropout=dropout)
self.fc = nn.Linear(hidden_dim * 2, num_classes)
def forward(self, x):
out = self.embedding(x)
out, _ = self.lstm(out)
out = self.fc(out[:, -1, :]) # 句子最后时刻的hidden state
return outDataset
制作dataset以便dataloader能够使用
import torch
from torch.utils.data import Dataset, DataLoader
class NewsTitleDataset(Dataset):
def __init__(self, X, y):
self.data = torch.LongTensor(X)
self.label = torch.LongTensor(y)
def __getitem__(self, idx):
return self.data[idx], self.label[idx]
def __len__(self):
return len(self.data)DataLoader
在定义dataloder前我们先定义一些模型超参数,该参数可以自行调节
sen_len = 12
batch_size = 128
n_epoch = 10
lr = 0.001
train_preprocess = Preprocess(train_x, sen_len, w2v_path=save_path)
embedding = train_preprocess.make_embedding(load=True)
train_x = train_preprocess.sentence_word2idx()
# 将 data 划分为 training data 和 validation data
X_train, X_val, y_train, y_val = train_x[:180000], train_x[180000:], train_y[:180000], train_y[180000:]
# 将 data 做成 dataset 供 dataloader 使用
train_dataset = NewsTitleDataset(X=X_train, y=y_train)
val_dataset = NewsTitleDataset(X=X_val, y=y_val)
# 将 data 转成 batch of tensor
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)Get embedding ...
loading word to vec model ...
total words: 30360
模型训练
import time
import numpy as np
# 加载模型
model = LSTM_Net(embedding, embedding_dim=250, hidden_dim=150, num_layers=2, num_classes=10, dropout=0.5, fix_embedding=True)
model = model.cuda()
# criterion
criterion = nn.CrossEntropyLoss()
# optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
# Training
best_acc = 0
for epoch in range(n_epoch):
epoch_start_time = time.time()
train_acc, train_loss = 0, 0
val_acc, val_loss = 0, 0
model.train() # 训练模式
for i, data in enumerate(train_loader):
optimizer.zero_grad()
# 前向传播
train_pred = model(data[0].cuda())
# 后向传播
loss = criterion(train_pred, data[1].cuda())
loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(train_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += loss.item()
model.eval() # 评估模型
with torch.no_grad():
for i, data in enumerate(val_loader):
val_pred = model(data[0].cuda())
loss = criterion(val_pred, data[1].cuda())
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == data[1].numpy())
val_loss += loss.item()
# 展示结果
print(f'Epoch [{epoch+1}/{n_epoch}] {time.time()-epoch_start_time:.4f} sec(s) Train Acc: {(train_acc / len(X_train)):.4f} Loss: {(train_loss / len(X_train)):.6f} | Val Acc: {val_acc / len(X_val):.4f} Loss: {val_loss / len(X_val):.6f}')
if (val_acc / len(X_val)) > best_acc:
best_acc = val_acc / len(X_val)
torch.save(model, './logs/lstm_cl.model')
print(f'saving model with acc {best_acc:.4f}')Epoch [1/10] 12.5952 sec(s) Train Acc: 0.8458 Loss: 0.003683 | Val Acc: 0.8786 Loss: 0.003035
saving model with acc 0.8786
Epoch [2/10] 12.6020 sec(s) Train Acc: 0.8907 Loss: 0.002629 | Val Acc: 0.8906 Loss: 0.002654
saving model with acc 0.8906
Epoch [3/10] 12.5632 sec(s) Train Acc: 0.8991 Loss: 0.002396 | Val Acc: 0.8902 Loss: 0.002658
Epoch [4/10] 12.5930 sec(s) Train Acc: 0.9050 Loss: 0.002251 | Val Acc: 0.8951 Loss: 0.002480
saving model with acc 0.8951
Epoch [5/10] 12.5931 sec(s) Train Acc: 0.9102 Loss: 0.002110 | Val Acc: 0.8978 Loss: 0.002456
saving model with acc 0.8978
Epoch [6/10] 12.7861 sec(s) Train Acc: 0.9154 Loss: 0.001967 | Val Acc: 0.8989 Loss: 0.002452
saving model with acc 0.8989
Epoch [7/10] 12.8262 sec(s) Train Acc: 0.9212 Loss: 0.001838 | Val Acc: 0.9004 Loss: 0.002465
saving model with acc 0.9004
Epoch [8/10] 12.7670 sec(s) Train Acc: 0.9252 Loss: 0.001716 | Val Acc: 0.9012 Loss: 0.002431
saving model with acc 0.9012
Epoch [9/10] 14.5936 sec(s) Train Acc: 0.9303 Loss: 0.001590 | Val Acc: 0.9006 Loss: 0.002502
Epoch [10/10] 19.8384 sec(s) Train Acc: 0.9358 Loss: 0.001462 | Val Acc: 0.9018 Loss: 0.002567
saving model with acc 0.9018
经过10次迭代后,模型在验证集中的准确度达到0.9018,说明模型还不错,大家可以尝试改动模型参数,看看预测准确度会不会进一步提高。



