门控循环单元(gated recurrent units, GRU)于2014被Cho等人提出。GRU和LSTM一样有专门的机制来确定应该何时更新隐状态,以及应该何时重置隐状态,但GRU没有单独的存储单元,即LSTM的记忆元。GRU是LSTM的一个变体,它结构更加简单,却能够提供和LSTM同等的效果,并且计算的速度明显更快。
现在我们从GRU的内部结构开始解读:
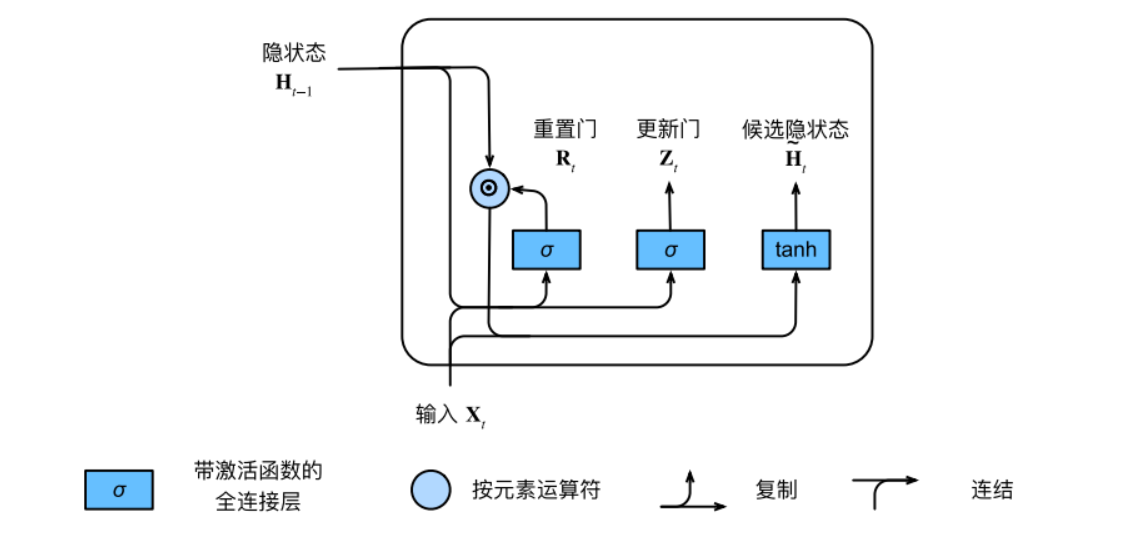
重置门和更新门
我们首先介绍重置门(reset gate)和更新门(update gate)。重置门控制着我们还想记住过去状态的数量;更新门决定着新状态保存旧状态信息的程度。这两个门的输入和LSTM一样,是当前时间步的输入和上一时间步的隐状态,它们的输出是由使用sigmoid激活函数的两个全连接层给出。因此它们的数学表达为:
$$R_{t}=\sigma({X_{t}W_{xr}+H_{t-1}W_{hr}+b_{r}})$$
$$Z_{t}=\sigma({X_{t}W_{xz}+H_{t-1}W_{hz}+b_{z}})$$
式中:$X_{t}\in R^{nxd}$是输入(样本个数:n,维度:d);$H_{t-1}\in R^{nxh}$是上一时间步的隐状态;$R_{t}\in R^{nxd}$和$Z_{t}\in R^{nxd}$分别是重置门和更新门;$W_{xr},W_{xz}\in R^{dxh}$和$W_{hr},W_{hz}\in R^{hxh}$是权重参数,$b_{r},b_{z}\in R^{1xh}$是偏置项。
候选隐状态
候选隐状态(candidate hidden state)$\overset{-}{H_{t}}\in R^{nxh}$的计算公式如下:
$$\overset{-}{H_{t}}=tanh(X_{t}W_{xh}+(R_{t}\bigodot H_{t-1})W_{hh}+b_{h})$$
式中$W_{xh}\in R^{dxh}$和$W_{hh}\in R^{hxh}$是权重参数,$b_{h}\in R^{1xh}$是偏置项,符号$\bigodot$是Hadamard积(按元素乘积)运算符。
重置门$R_{t}$可以控制以往状态的影响程度, 当$R_{t}$中所有项接近1时,保留前一隐状态所有影响。当$R_{t}$中所有项接近0时,候选隐状态是以$X_{t}$作为输入的多层感知机的结果。
以上计算流程可以用下图表示:
隐状态
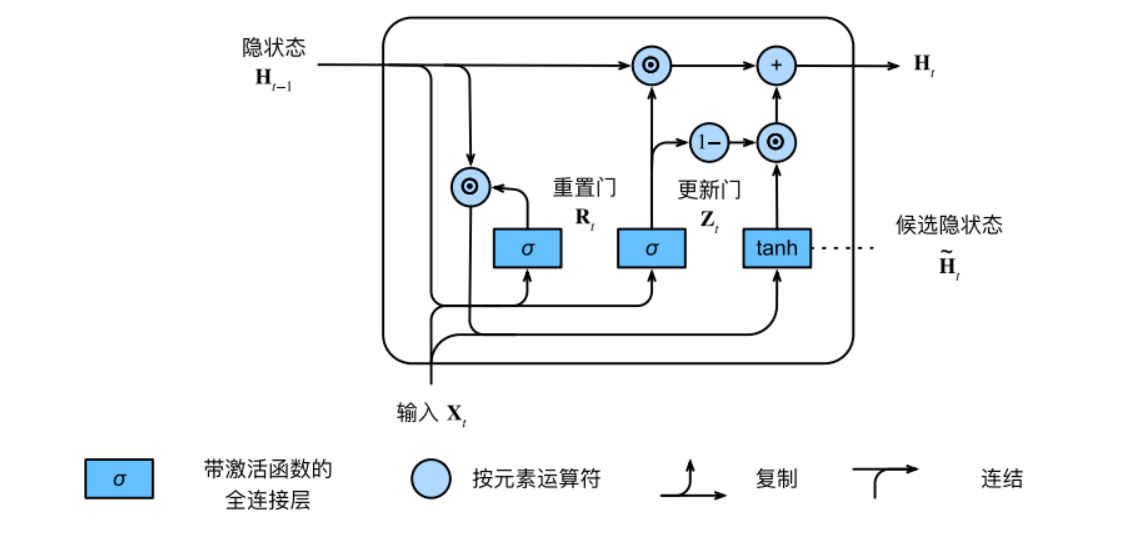
隐状态$H_{t}\in R^{nxh}$通过更新门$Z_{t}$来确定它多大程度上来自与旧的状态$H_{t-1}$和当前候选状态$\overset{-}{H_{t}}$,它的具体公式为:
$$H_{t}=Z_{t}\bigodot H_{t-1}+(1-Z_{t})\bigodot \overset{-}{H_{t}}$$
每当更新门$Z_{t}$中所有项接近1时,模型就倾向于只保存旧状态。此时,来自$X_{t}$的信息基本上被忽略。相反,当$Z_{t}$中所有项接近0时,新的隐状态$H_{t}$就会接近候选隐状态$\overset{-}{H_{t}}$这些设计可以帮助我们处理循环神经⽹络中的梯度消失问题,并更好地捕获时间步距离很⻓的序列的依赖关系。
此时GRU一个神经元一个完整的内部结构就可以用下图表示:
用LSTM,我们最后将最新的隐状态作为输入进入另一个网络,则可实现分类或回归等模型。
GRU网络代码
同LSTM我们可以调用pytorch里面的API实现一个简单的GRU网络
import torch
import torch.nn as nn
class GRU_Net(nn.Module):
def __init__(self, embedding, embedding_dim, hidden_dim, num_layers, output_dim, dropout=0.5, fix_embedding=True):
"""
embedding: 词典
embedding_dim: 词向量的维度
hidden_dim: GRU神经元个数
num_layers: GRU的层数
output_dim: 隐藏层输出的维度(分类的数量)
"""
super(GRU_Net, self).__init__()
# 制作 embedding layer
self.embedding = torch.nn.Embedding(embedding.size(0), embedding.size(1))
self.embedding.weight = torch.nn.Parameter(embedding)
# 如果 fix_embedding 为 False,在训练过程中,embedding 也会跟着被训练
self.embedding.weight.requires_grad = False if fix_embedding else True
self.embedding_dim = embedding.size(1)
self.gru = nn.GRU(embedding_dim, hidden_dim, num_layers=num_layers, bidirectional=True, batch_first=True, dropout=dropout)
self.fc = nn.Linear(hidden_dim * 2, output_dim)
def forward(self, x):
out = self.embedding(x)
out, _ = self.gru(out)
out = self.fc(out[:, -1, :]) # 句子最后时刻的hidden state
return out用LSTM同样的例子,经过这个网络得出在验证集中准确率最高为0.9024,和LSTM模型的准确度差不多,但运行时间个人明显感觉短了很多。
与LSTM间的异同
两者相似之处:引用了门结构,并在t-1时刻到t时刻信息的传递引用了新的成分(候选隐状态,在LSTM中是记忆元),不再像传统RNN只利用了当前时刻的输入和上一时刻的隐状态。这个相同之处带来了两个好处:
①能够保存长期序列中的信息,且不会随时间而清除或因为与预测不相关而移除。
②有效创建了绕过多个时间步骤的快捷路径。这些捷径允许误差更容易反向传播,不至于像传统RNN那样迅速消散,从而解决了梯度消失的问题。
两者不同之处:
①对记忆内容传递程度的控制。LSTM用output gate控制传递程度,传递给下一个unit;而GRU是完全传递给下一个unit,不做任何控制。
②对候选内容的控制;LSTM计算候选记忆元不对上一信息做任何控制;而GRU计算候选隐状态时利用reset gate对上一时刻的信息进行控制。



