写在前面:这个部分主要记录一些关于深度学习相关论文的阅读,由于个人还是刚接触深度学习不久,所以前面需要补充一些很早的论文以巩固自己知识的不足。今天记录最近学的一篇论文Sequence to Sequence Learning with Neural Networks。这篇论文研究的是机器翻译领域,作者使用的方法是利用一个多层的 LSTM 将输入文本编码成一个向量,这个向量可以视为整个输入句子的抽象表示。然后用另一个 LSTM 将前面编码的向量解码成目标句子。作者将其应用在 WMT’14 数据集上英语到法语的翻译任务,并在整个测试集上得到的 BLEU score 为34.8。下面我门结合Dive into Deep Learning这本书的相关章节和这篇论文了解 seq2seq 的一般概念,并陈述构建模型时需要用的一些方法。
seq2seq
最常用的 seq2seq 模型其实就是encoder-decoder模型。encoder-decoder模型通常使用 RNN 将一段文本作为输入编码(encoder)成一个向量,这个向量可以视为整个输入句子的抽象表示。然后,该向量通过第二个 RNN 解码(decoder),该 RNN 通过一次生成一个单词来学习目标句子(也就是另一种语言的句子)。下图演示了将 seq2seq 模型用于英文到中文的翻译。
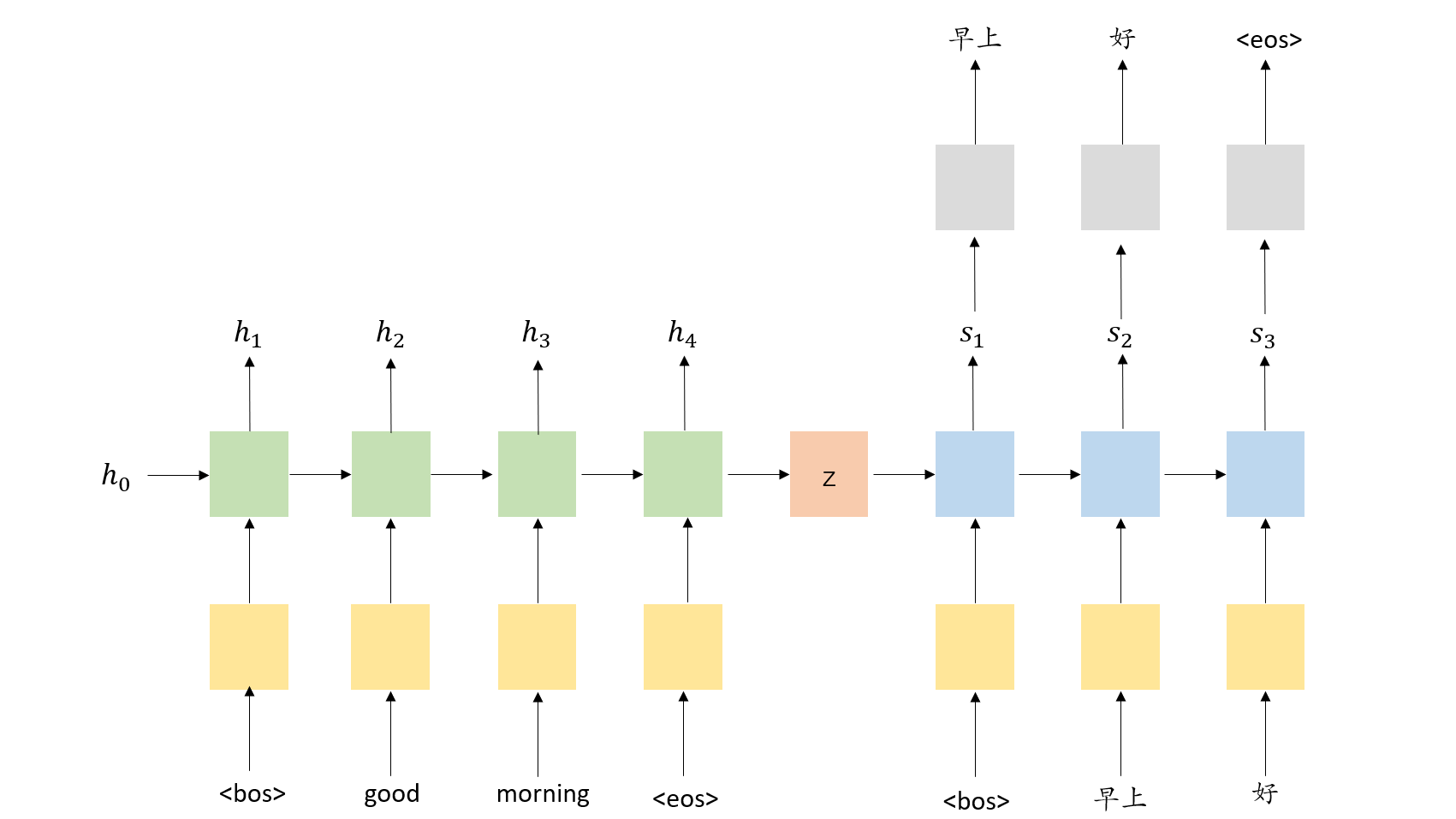
Encoder
图中展示了一个简单的翻译模型,模型中用<bos>和<eos>分别表示开始词元和结束词元。它的输入句子是”good morning“,它首先通过embedding层转换为对应的词向量,然后再进入编码器(encoder)。在每一个时间步,进入编码器RNN含有embedding$x_{t}$和上一时间步隐状态$h_{t-1}$,然后编码器RNN产生新的隐状态$h_{t}$。我们可以抽象地把这个隐状态代表为前面的词元。该时间步的计算可以用以下公式表达:
$$h_{t}=EncoderRNN(e(x_{t},h_{t-1}))$$
在这里,我们通常使用LSTM或GRU这样的term RNN。假设,输入$X={x_{1},x_{2},…,x_{T}}$,式中 $x_{1}$=<bos>,$x_{2}$=good,etc 。编码器初始的隐状态 $h_{0}$ 通常初始化为0或者已经学习好的参数。一旦最后的词元 $x_{T}$ 通过embedding层进入编码器RNN,我们利用最后的隐状态 $h_{T}$ 来作为文本向量,并把它赋值给z :$h_{T}=z$
Decoder
现在我们拥有文本向量z,我们可以开始将其解码成目标句子——”早上好“。同样我们用
$$s_{t}=DecoderRNN(d(y_{t},s_{t-1}))$$
在解码器中,我们需要将隐状态转换为对应的单词,因此在每一个时间步,我们通过一个线性层通过$s_{t}$去预测下一个在文本出现的单词$\overset{-}{y_{t}}$
$$\overset{-}{y_{t}}=f(s_{t})$$
解码器中的单词是随着时间步一个接一个地生成。我们通常使用<bos>作为解码器的第一个输入$y_{1}$,但是对于接下来的输入$y_{t>1}$,我们有时使用在目标句子中下一个单词,有时也会使用经解码器预测的下一个单词$\overset{-}{y_{t}}$,这在机器翻译中被叫做teacher forcing。使用teacher-forcing,在训练过程中,可以加快模型的训练,使得模型会有较好的效果。但是在测试的时候因为不能得到目标句子的支持,存在训练测试偏差,模型会变得脆弱。
训练模型时,我们通常知道目标句子有多少单词,一旦解码器输入目标单词,模型就会停止生成单词。但在测试模型时,解码器会不断生成单词,直到模型输出<eos>或生成一定数量的单词之后,模型就停止生成单词。
一旦模型得到了预测目标句子$\overset{-}{Y}={\overset{-}{y_{1}},\overset{-}{y_{2}},…,\overset{-}{y_{t}}}$,我们将其和目标句子$Y={y_{1},y_{2},…,y_{t}}$进行比较,计算出误差,利用该误差就可以更新模型的所有参数。
技巧
数据预处理
- 将文本词元化,在机器翻译中我们更喜欢单词级词元化。对训练数据的文本序列进行词元,其中每个词元要么是一个词,要么是一个标点符号。
- 分别为源语言和目标语言构建两个字典——int2word 和 word2int (这两个字典将单词和整数一一对应)。同时为了减少数据噪声的影响,我们将出现次数少于2次的低频率词元视为未知 <unk> 词元。除此之外,我们还指定一些额外的特定词元,例如在小批量时用于将序列填充到相同长度的填充词元 <pad> ,以及序列的开始词元 <bos> 和结束词元 <eos> 。
- 为了提高计算效率,我们可以通过截断和填充方式实现每个序列都具有相同的长度。当文本序列词元数目少于规定数据时,我们将继续在其末尾添加特定的 <pad> 词元。反之,我们将截断文本序列,只取前指定数目个词元,丢弃剩余词元。
搭建模型
这一部分可以参考论文




