在前面我们学习过自注意力模型,自注意力模型拥有CNN并行运算和RNN挖掘序列中的关系两大优势。因此,使用自注意力模型来设计深度架构是很有吸引力的。对比之前仍然依赖RNN来实现输入表示的类似注意力模型,Transformer模型完全基于自注意力机制,不但实现了快速并行计算,还可以像DNN一样将模型增加到非常深的深度。Transformer由论文Attention is All You Need提出,最初是应用于文本数据上的序列到序列学习,但现在已经推⼴到各种现代的深度学习中,例如语⾔、视觉、语⾳和强化学习领域。
Transformer的整体架构如下图所示,是一个Encoder-Decoder架构。Transformer是由Encoder和Decoder组成,这两个部分是基于自注意力的模块叠加而成的,源序列和目标序列先词向量化(embedding),然后加上位置编码(positional encoding),再分别输入到Encoder和Decoder中。
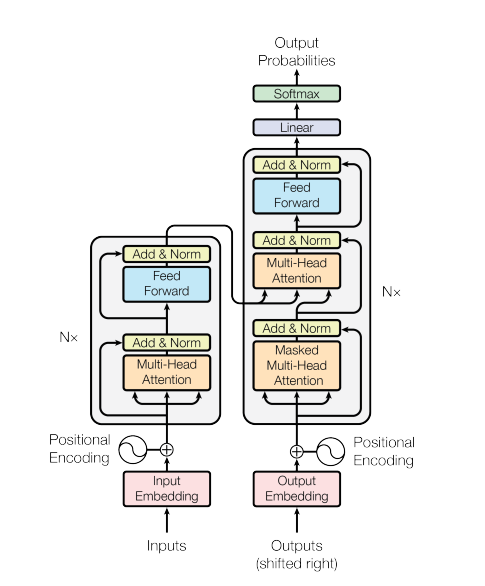
Encoder和Decoder
从宏观角度来看,transformer的Encoder是由多个相同的层叠加而成的,每个层都有两个子层(sublayer)。第一个子层是多头自注意力(multi-head self-attention)层;第二个子层是基于位置的前馈网络(position-wise feed-forward network)层。同时受残差网络的启发,每个子层都采用了残差连接(residual connection),并在残差连接的加法计算之后,使用层规范化(layer normalization)。在计算编码器的自注意力时,查询、键和值都来自前一个layer的输出。由于使用了残差连接,Transformer的每一个layer都将输出一个d维表示向量。
Transformer的Decoder也是由多个相同的层叠加而成的。除了Encoder中描述的两个子层之外,Decoder还在两个子层之间插入了第三个子层,称为编码器 - 解码器注意力(encoder-decoder attention)层。Decoder的子层同Encoder一样,使用了残差连接和层规范化。在编码器-解码器注意⼒中,查询来⾃前Decoder前一个layer的输出,而键和值来⾃Encoder的输出。在Decoder自主意力中,查询、键和值都来自于Decoder上一个layer的输出。但是和Encoder自主意力不同的是,Decoder的每个位置只能考虑位置之前的所有位置。这种掩蔽(masked)注意力保留了自回归(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
自注意力
有关这方面的详细推导请看这篇文章,在这节我们主要讲解编码器 - 解码器注意力层是怎么运作的。
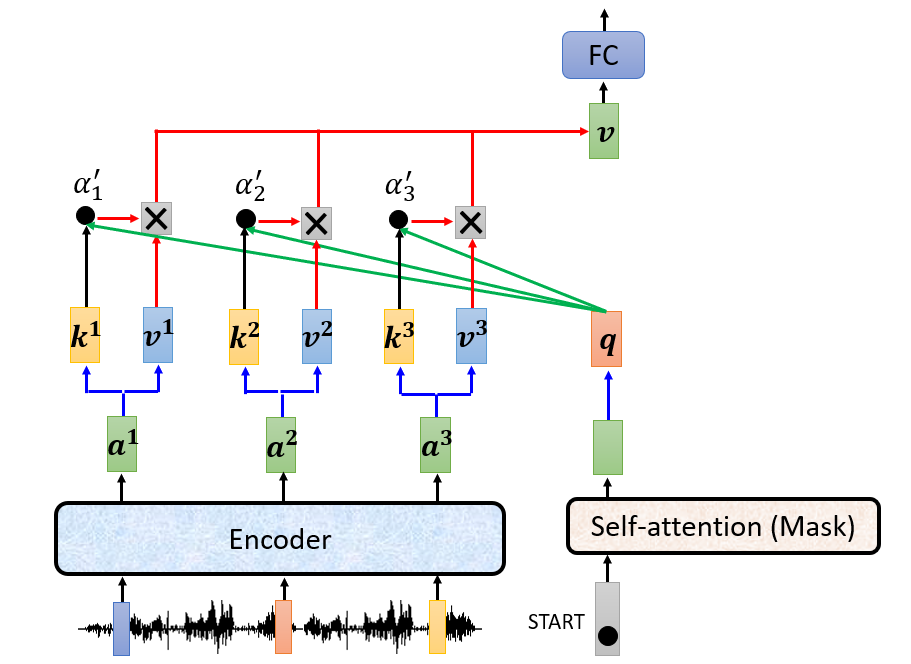
以语言识别为例,如上图假定Transformer的Encoder将一段声音讯号编码成$a^{1}、a^{2}、a^{3}$三个向量,而Transformer的Decoder获取第一个表示开始的向量,将其输入到掩蔽多头自主意力层,得到一个向量,将该向量的查询q和Encoder得到的三个向量的键、值做self-attention处理得到向量v,再把向量v作为Decoder的基于位置的前馈网络层中,最后得到目标词汇。
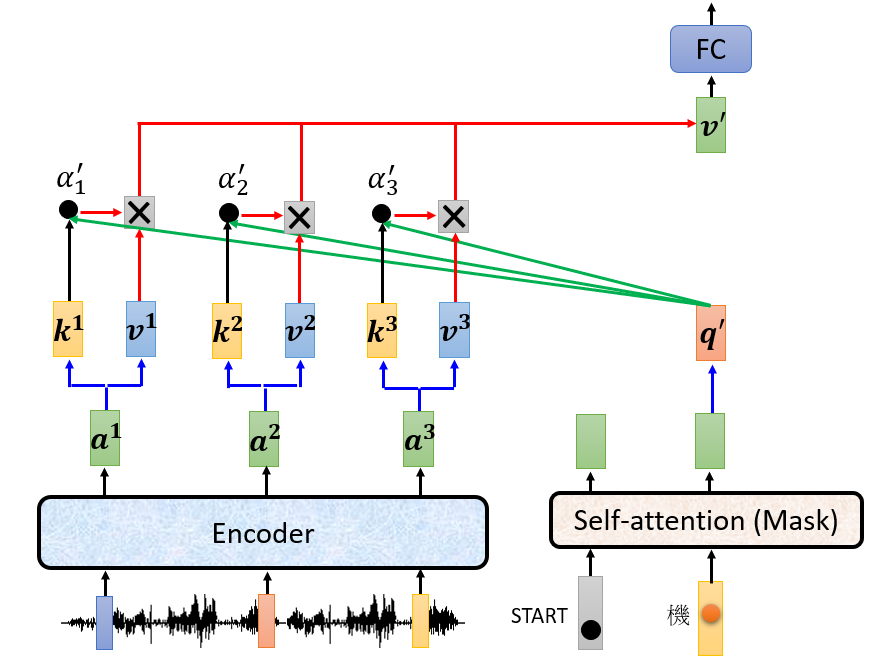
将得到目标词汇对应的向量连同start对应的向量作为Decoder的输出,经过掩蔽多头自主意力层得到另一个向量,将该向量的查询$q^{‘}$和Encoder得到的三个向量的键、值做self-attention处理得到向量$v^{‘}$,反复进行这样的操作直到Decoder输出结束的标志。
基于位置的前馈网络层
该层包含两个线性变换,在这两个线性变化之间有一个ReLU激活函数。
$$FFN(x)=max(0,xW_{1}+b_{1})W_{2}+b_{2}$$
Embedding和softmax
与其他序列转换模型类似,我们使用已经学习好的Embedding层将源序列和目标序列转换维度是$d_{model}$的向量。同时在Transformer Decoder的最后,使用线性变换和softmax函数将编码器输出转换为预测目标词汇的概率。
位置编码
由于Transformer模型不包含递归和卷积操作,整个运行过程都是应用self-attention实现计算的平行化,因此Transformer没有考虑输入序列的先后顺序。为了让模型利用序列的顺序,我们需要给模型注入一些关于词汇在序列中相对或绝对位置的信息。为此,Transformer在编码器和解码器的输入加入了位置编码。位置编码和Embedding后的词向量具有相同的维度$d_{model}$,将这两个向量相加,就可以获得序列的位置资讯。
位置编码计算为:
$$PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})$$
$$PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})$$
式中,$pos\in postion_{inputs},i\in (0,1,…,d_{model}/2)$
训练和翻译
假设有一个英文和其对应的中文元组:
(['BOS','machine','learning','EOS'],
['BOS','机器','学习','EOS'])假设我们通过大量的数据训练好了Transformer,数据的格式如下:
- 英文部分的输入为:BOS machine learning EOS;
- 中文部分的输入为:BOS 机器 学习;
- 标签为:机器 学习 EOS 用于CrossEntropy更新模型参数
翻译时:
- 英文序列作为输入;
- Encoder输出max_output_len个词向量;
- 将标志符号BOS作为中文的第一个tokens,结合Encoder的输出输入到Decoder中得到关于目标词汇的概率,取概率最大对应的词汇作为输出结果,再将该词汇对应的词向量作为新的中文输入词向量,这样循环下去一次得到max_output_len个输出结果,即得到输出的中文分词列表;
- 顺着列表检查分词,如果出现标志符号
EOS就截取前面的分词组成中文结果。
参考资料
[1] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[2] 李宏毅 机器学习2021



