前言
BERT的全称是Bidirectional Encoder Representations from Transformers(来自Transformers的双向编码器表示),BERT基于Transformer,Transformer在初始论文中是用于Seq2Seq任务中,其Encoder部分后续被迁移到各种场景,逐渐演化成一种通用的特征提取器。BERT 通过使用预训练的 Transformer编码器,能够基于其双向上下文表示任何词元。在下游任务的监督学习过程中,BERT将输入表示到一个添加的输出层中,根据任务的性质对模型架构进行最小的更改,例如预测每个词元与预测整个序列。同时,BERT对预训练Transformer编码器的所有参数进行微调,而额外的输出层将从头开始训练。
在BERT的原始论文BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding 中,BERT的描述分为三个部分:输入表示、预训练任务和下游任务。
BERT的输入表示
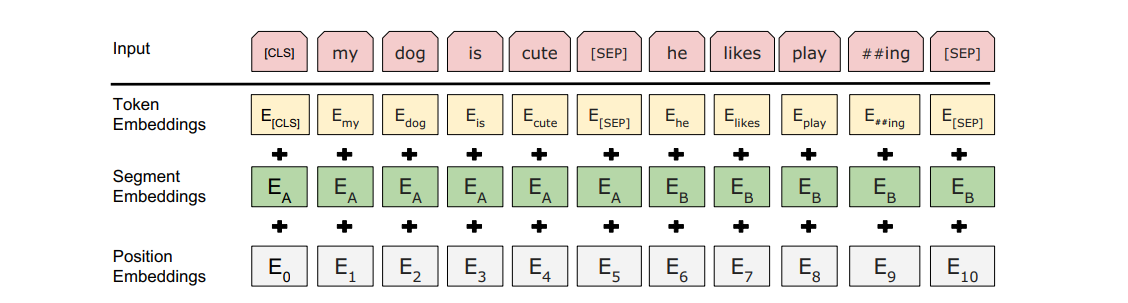
在自然语言处理中,有些任务(如情感分析)以单个文本为输入,而有些任务(如自然语言推断)以一对文本序列作为输入。当输入为单个文本时,BERT输入序列是特殊类别词元“<cls>”、⽂本序列的标记、以及特殊分隔词元“<sep>”的连结。当输入为文本对是,BERT输入序列是“<cls>”、第⼀个⽂本序列的标记、“<sep>”、第⼆个⽂本序列标记、以及“<sep>”的连结。
BERT选择Transformer编码器作为其双向架构。在Transformer编码器中,位置嵌入被加到输入序列的每个位置。然而,与原始Transformer编码器不同,BERT使用可学习的位置嵌入,其输入为词元嵌入(Token Embeddings)、片段嵌入(Segment Embeddings)和位置嵌入(Position Embeddings)的和。
预训练任务
前面我们给出了输入文本的每个词元和插入的特殊标记“<cls>”及“<seq>” 的BERT表示。接下来,我们将使⽤这些表⽰来计算预训练BERT的损失函数。预训练包括以下两个任务:掩蔽语言模型和下一句预测。
掩蔽语言模型(Masked Language Modeling, Masked LM)
根据直觉,我们有理由相信deep bidirectional model比left-to-right model(如单向LSTM)或者浅级连接的left-to-right model和right-to-left model(如双向LSTM)更加强大。为了双向编码上下文以表示每个词元,BERT随机掩蔽词元并使用来自上下文的词元以自监督(self-supervised)的方式预测掩蔽词元。此任务称为掩蔽语言模型。这个模型可以用下图表示,假设输入是机器学习。
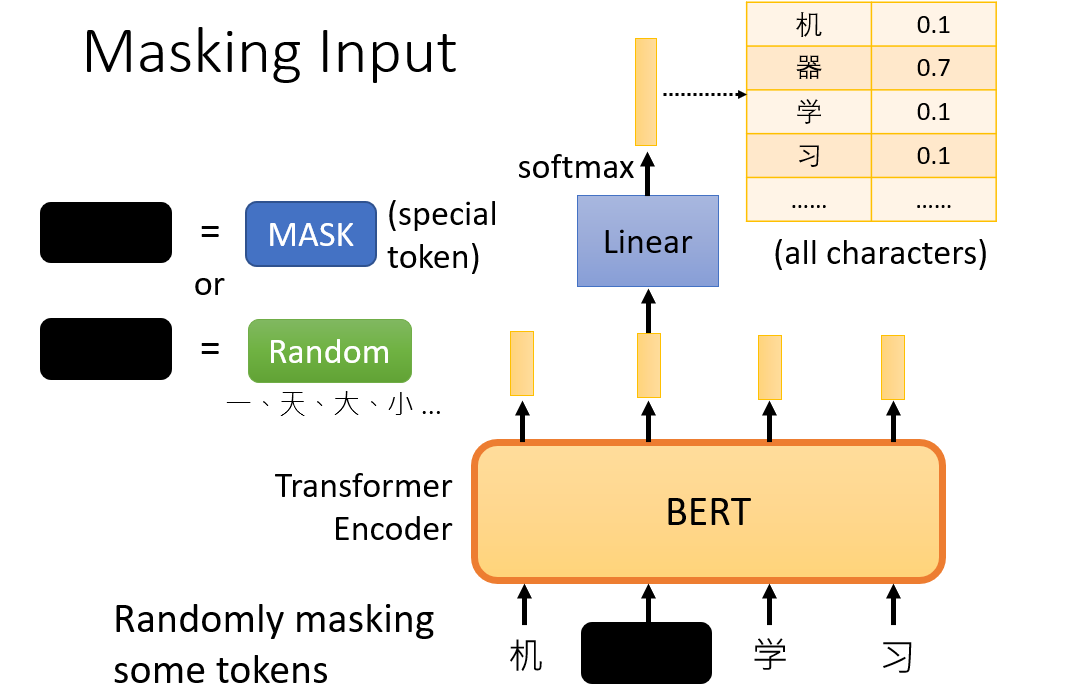
在这个预训练任务中,将随机选择15%的词元作为预测的掩蔽词元。要预测⼀个掩蔽词元而不使⽤标签作弊,
⼀个简单的⽅法是总是⽤⼀个特殊的“<mask>”替换输⼊序列中的词元。然而,⼈造特殊词元“<mask>”不
会出现在微调中。为了避免预训练和微调之间的这种不匹配,如果为预测而屏蔽词元(例如,在“my dog is hairy ”中选择掩蔽和预测“hairy”),则在输⼊中将其替换为:
- 80%概率为特殊的“<mask>“词元(例如,“my dog is hairy ”变为“my dog is <mask>”)
- 10%概率为随机词元(例如,“my dog is hairy ”变为“my dog is apple”)
- 10%概率为不变的标签词元(例如,“my dog is hairy ”变为“my dog is hairy”)
注意在15%的词元中,有10%的概率替换为随机词元。这种偶然的噪声鼓励BERT在其双向上下文编码中不那么偏向于掩蔽词元,而这种影响在标签保持不变时更加深刻。
总的来说Masked LM的目标是预测出被掩蔽的单词,相当于做一个完形填空,做完形填空的任务有利于BERT学会理解文本的上下文信息。
下⼀句预测(Next Sentence Prediction, NSP)
虽然掩蔽语言模型能够双向上下文来表示单词,但它不能显式地表示文本对之间的逻辑关系,在这一些自然语言处理任务中尤为重要(如QA问答系统和自然语言推断)。为了帮助理解两个文本序列之间的关系,BERT在预训练中考虑了一个二元分类任务——下一句预测。在为预训练生成句子对时,有⼀半的时间它们确实是标签为“Yes”的连续句⼦。但在另⼀半的时间⾥,第⼆个句⼦是从语料库中随机抽取的,标记为“No”。
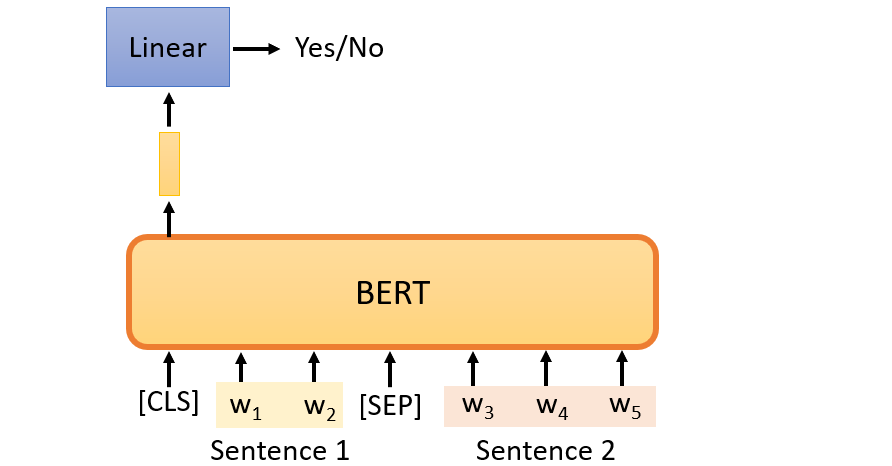
这个模型可以用上图表示,输入是两个句子,也就是文本对的输入格式。BERT输出是将特殊词元“<cls>” 编码后的向量,由于Transformer编码器中的自主意力,特殊词元“<cls>”的BERT表⽰已经对输⼊的两个句⼦进⾏了编码。再将编码后的向量输入一个多层感知机来预测第二个句子是否是BERT输入序列中第一个句子的下一句。
用于预训练BERT的数据集
为了预训练BERT模型,我们需要以理想的格式生成数据集,以便于上述两个预训练任务。在论文中,预训练的语料库有两个:BooksCorpus(8亿个单词)、English Wikipedia(25亿个单词)。对于English Wikipedia,只提取文本段落而忽略列表、表格和标题。
BERT下游任务
基于预训练后的BERT模型,可以将其融合到各种NLP任务中。BERT中每个词没有固定的词向量,是根据词的上下文来动态产生当前词的词向量。
在论文中,列出了四大BERT的下游任务:
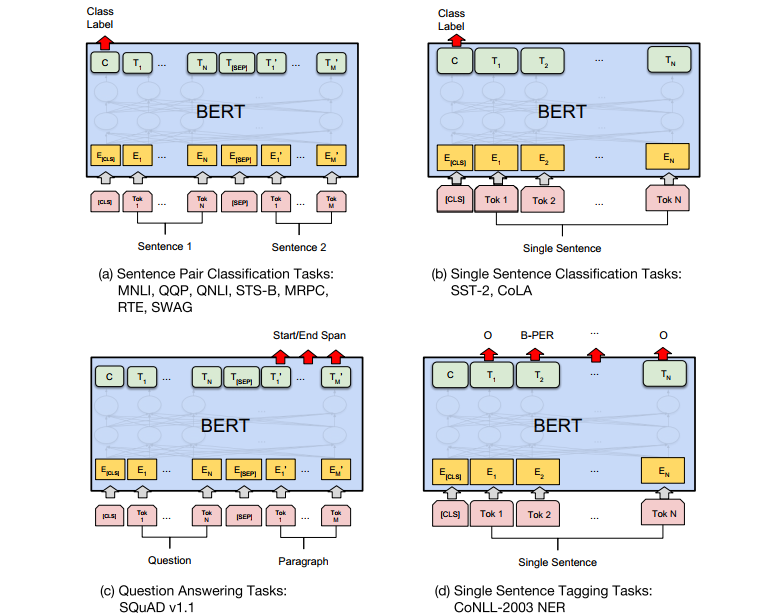
第一个任务是句子对的分类任务,第二个是单一句子的分类任务,第三个是问答系统,第四个是单一句子的标注任务。它们均可在预训练BERT的输出上接入相应的结构实现,最后基于任务的训练数据进行微调实现。其中任务一和任务二是将特殊词元“<cls>” 编码后的向量输入一个分类器实现,任务四是将单个句子里每个词元经过BERT编码后的向量分别输入一个分类器中实现。
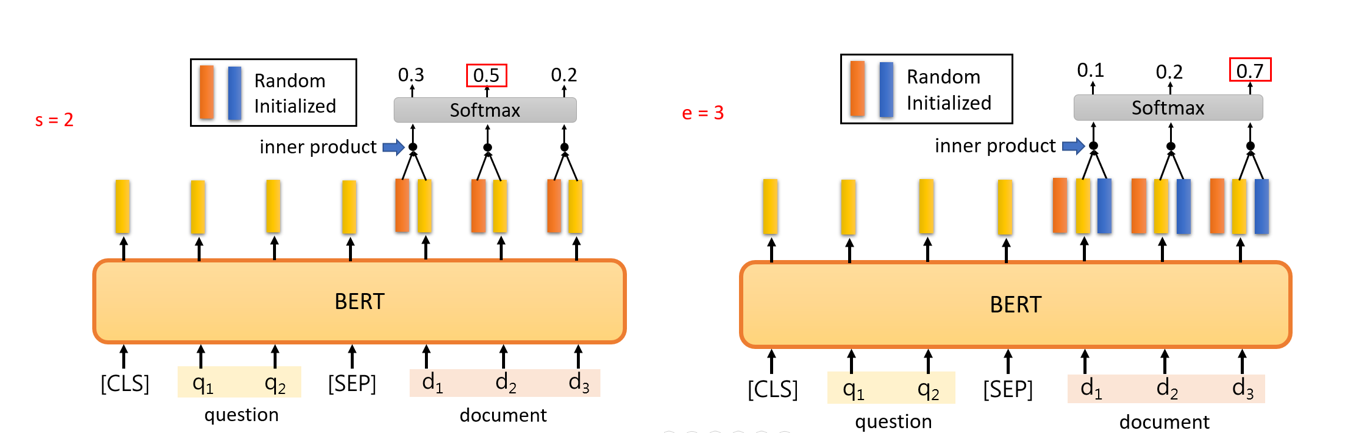
对于任务三,输入是一个问题加一个文件,输出是输入文件对应答案的开始和结束位置。由此可以看出该模型实现的要求是询问的答案可以在文件中找到,那么这个任务怎么实现呢?如上图,我们初始化两个和编码词元后的向量相同长度的vector,图中橙色的向量用于确认答案在文件中开始词元的序号(位置),蓝色的向量用于确认结束词元的序号。将这两个向量分别乘于文件中的词元经过BERT编码的向量,然后通过一个softmax层找到最大值对应的序号即可得到答案。如图中s=2,e=3,如果文件的内容是how to use BERT,则答案为use BERT。因此在这个任务中,我们需要训练的参数是图中的两个向量。
参考资料
[2] 李宏毅 机器学习2021



