- 目标:用深度神经网络(DNN)解决一个回归问题,了解训练基础DNN的技巧
- 任务描述: 给定美国特定州过去三天有关COVID-19的调查,然后预测第3天新检测阳性病例的百分比
导入一些包
# PyTorch
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# For data preprocess
import numpy as np
import csv
import os
# For plotting
import matplotlib.pyplot as plt
myseed = 42069 # set a random seed for reproducibility
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
np.random.seed(myseed)
torch.manual_seed(myseed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(myseed)定义一些函数
def get_device():
''' Get device (if GPU is available, use GPU) '''
return 'cuda' if torch.cuda.is_available() else 'cpu'
def plot_learning_curve(loss_record, title=''):
''' Plot learning curve of your DNN (train & dev loss) '''
total_steps = len(loss_record['train'])
x_1 = range(total_steps)
x_2 = x_1[::len(loss_record['train']) // len(loss_record['dev'])]
plt.figure(figsize=(6, 4))
plt.plot(x_1, loss_record['train'], c='tab:red', label='train')
plt.plot(x_2, loss_record['dev'], c='tab:cyan', label='dev')
plt.ylim(0.0, 5.)
plt.xlabel('Training steps')
plt.ylabel('MSE loss')
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
def plot_pred(dv_set, model, device, lim=35., preds=None, targets=None):
''' Plot prediction of your DNN '''
if preds is None or targets is None:
model.eval()
preds, targets = [], []
for x, y in dv_set:
x, y = x.to(device), y.to(device)
with torch.no_grad():
pred = model(x)
preds.append(pred.detach().cpu())
targets.append(y.detach().cpu())
preds = torch.cat(preds, dim=0).numpy()
targets = torch.cat(targets, dim=0).numpy()
plt.figure(figsize=(5, 5))
plt.scatter(targets, preds, c='r', alpha=0.5)
plt.plot([-0.2, lim], [-0.2, lim], c='b')
plt.xlim(-0.2, lim)
plt.ylim(-0.2, lim)
plt.xlabel('ground truth value')
plt.ylabel('predicted value')
plt.title('Ground Truth v.s. Prediction')
plt.show()数据预处理
有三种数据集:训练集、验证集和测试集
Dataset
这部分需要实现的功能如下:
- 读取.csv文件,将covid.train.csv划分为训练集和验证集
- 提取数据特征,并进行归一化处理
class COVID19Dataset(Dataset):
''' 用于加载并对COVID19数据集进行预处理'''
def __init__(self, path, mode='train', target_only=False):
self.mode = mode
# 读取数据为numpy arrays格式
with open(path, 'r') as fp:
data = list(csv.reader(fp))
data = np.array(data[1:])[:, 1:].astype(float) # 不读取行列的注释
if not target_only:
feats = list(range(93)) # 考虑所有影响因素
else: # 作业实现部分
# TODO: Using 40 states & 2 tested_positive features (indices = 57 & 75)
feats = list(range(40))
feats.append(57)
feats.append(75)
if mode == 'test':
# 测试数据
# data: 893 x 93 (40 states + day 1 (18) + day 2 (18) + day 3 (17))
data = data[:, feats]
self.data = torch.FloatTensor(data)
else:
# 训练数据,用于划分训练集和验证集
# data: 2700 x 94 (40 states + day 1 (18) + day 2 (18) + day 3 (18))
target = data[:, -1]
data = data[:, feats]
# 将训练数据划分为训练集和测试集(9 : 1)
if mode == 'train':
indices = [i for i in range(len(data)) if i % 10 != 0]
elif mode == 'dev':
indices = [i for i in range(len(data)) if i % 10 == 0]
# 将数据转成tensors格式
self.data = torch.FloatTensor(data[indices])
self.target = torch.FloatTensor(target[indices])
# 归一化处理(你可以尝试将这部分去除,看结果会变成什么样子)
self.data[:, 40:] = \
(self.data[:, 40:] - self.data[:, 40:].mean(dim=0, keepdim=True)) \
/ self.data[:, 40:].std(dim=0, keepdim=True)
self.dim = self.data.shape[1]
print('Finished reading the {} set of COVID19 Dataset ({} samples found, each dim = {})'
.format(mode, len(self.data), self.dim))
def __len__(self):
# 返回数据的长度
return len(self.data)
def __getitem__(self, idx):
# 每次返回一个样本
if self.mode in ['train', 'dev']:
# 训练
return self.data[idx], self.target[idx]
else:
# 测试(没有目标值)
return self.data[idx]DataLoader
以小批量的格式从定义好的Dataset中加载数据
def prep_dataloader(path, mode, batch_size, target_only=False):
''' 生成一个数据集,将其输入到指定的dataloader中 '''
dataset = COVID19Dataset(path, mode=mode, target_only=target_only)
dataloader = DataLoader(
dataset, batch_size,
shuffle=(mode == 'train'))
return dataloader模型实现
构建模型
模型简单由具有ReLU激活函数的全连接层组成
class SimpleNet(nn.Module):
''' 实现一个简单由几个全连接层组成的深度神经网络 '''
def __init__(self, input_dim):
super(SimpleNet, self).__init__()
# 你可以对这部分的网络结构进行修改
self.net = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 32),
nn.ReLU(),
nn.Linear(32, 1)
)
def forward(self, x):
return self.net(x).squeeze(1) # 二维变成一维,数字对应去除的维度序号(从0开始)模型训练
def train(tr_set, dv_set, model, config, device):
''' 训练模型 '''
n_epochs = config['n_epochs'] # 最大迭代次数
optimizer = getattr(torch.optim, config['optimizer'])(
model.parameters(), **config['optim_hparas']) # 优化算法optimizer
criterion = nn.MSELoss(reduction='mean') # 损失函数criterion
min_mse = 1000 # 用于记录验证时最小的loss
loss_record = {'train': [], 'dev': []} # 记录训练损失
early_stop_cnt = 0 # 如果迭代过程中,超过设定迭代次数,模型的最小loss还没更新就停止迭代
for epoch in range(n_epochs):
model.train() # 将模型设置为训练模式
for x, y in tr_set:
optimizer.zero_grad() # 将梯度初始为0
x, y = x.to(device), y.to(device)
pred = model(x) # 前向传播(计算模型输出)
loss = criterion(pred, y) # 计算loss
loss.backward() # 后向传播(计算梯度)
optimizer.step() # 更新模型参数
loss_record['train'].append(loss.detach().cpu().item())
# 每次迭代后,在验证集中验证你的模型
dev_mse = dev(dv_set, model, device)
if dev_mse < min_mse:
# 当模型性能提升时保存模型
min_mse = dev_mse
print(f'Saving model (epoch = {epoch+1:4d}, loss = {min_mse:.4f})')
torch.save(model.state_dict(), config['save_path']) # 保存模型到指定的路径
early_stop_cnt = 0 # 每次模型性能改进,将该值变为0
else:
early_stop_cnt += 1 # 每次迭代后,模型性能未提升则加1
loss_record['dev'].append(dev_mse)
if early_stop_cnt > config['early_stop']:
# 如果你的模型在指定迭代次数后,模型性能仍为改进,则停止训练
break
print(f'Finished training after {epoch} epochs')
return min_mse, loss_record模型验证
def dev(dv_set, model, device):
model.eval() # 将模型设置为评估模式
criterion = nn.MSELoss(reduction='mean') # 损失函数criterion
total_loss = 0
for x, y in dv_set:
x, y = x.to(device), y.to(device)
with torch.no_grad(): # 不允许梯度计算
pred = model(x) # 前向传播
mse_loss = criterion(pred, y) # 计算loss
total_loss += mse_loss.detach().cpu().item() * len(x) # 总loss
total_loss = total_loss / len(dv_set.dataset) # 平均loss
return total_loss模型测试
def test(tt_set, model, device):
model.eval()
preds = []
for x in tt_set:
x = x.to(device)
with torch.no_grad():
pred = model(x)
preds.append(pred.detach().cpu())
preds = torch.cat(preds, dim=0).numpy() # 连接所有预测并转换为numpy数组
return preds设置超参数
config中包含模型训练的超参数(可以进行调节)和保存模型的路径
device = get_device()
os.makedirs('models', exist_ok=True) #
target_only = False
# 可以进行调节来提升模型性能
config = {
'n_epochs': 3000, # 最大迭代次数
'batch_size': 270, # dataloader的最小批量
'optimizer': 'SGD', # 参数优化算法
'optim_hparas': { # optimizer的超参数
'lr': 0.001, # SGD的学习率
'momentum': 0.9 # SGD的momentum
},
'early_stop': 200, # 自模型上次改进以后的最多迭代次数
'save_path': 'models/model.pth' # 模型保存路径
}加载数据和模型
tr_path = './data/covid.train.csv' # 训练数据路径
tt_path = './data/covid.test.csv' # 测试数据路径
tr_set = prep_dataloader(tr_path, 'train', config['batch_size'], target_only=target_only)
dv_set = prep_dataloader(tr_path, 'dev', config['batch_size'], target_only=target_only)
tt_set = prep_dataloader(tt_path, 'test', config['batch_size'], target_only=target_only)Finished reading the train set of COVID19 Dataset (2430 samples found, each dim = 93)
Finished reading the dev set of COVID19 Dataset (270 samples found, each dim = 93)
Finished reading the test set of COVID19 Dataset (893 samples found, each dim = 93)
model = SimpleNet(tr_set.dataset.dim).to(device) # 构建模型开始训练
model_loss, model_loss_record = train(tr_set, dv_set, model, config, device)Saving model (epoch = 1, loss = 196.5020)
Saving model (epoch = 2, loss = 64.4406)
Saving model (epoch = 3, loss = 16.0075)
Saving model (epoch = 4, loss = 7.1638)
Saving model (epoch = 5, loss = 6.9936)
Saving model (epoch = 6, loss = 4.3199)
Saving model (epoch = 7, loss = 2.8746)
Saving model (epoch = 8, loss = 2.3495)
Saving model (epoch = 9, loss = 2.0699)
Saving model (epoch = 10, loss = 1.8842)
Saving model (epoch = 11, loss = 1.7374)
Saving model (epoch = 12, loss = 1.6552)
Saving model (epoch = 13, loss = 1.5494)
Saving model (epoch = 14, loss = 1.4657)
Saving model (epoch = 16, loss = 1.3691)
Saving model (epoch = 18, loss = 1.2820)
Saving model (epoch = 19, loss = 1.2714)
Saving model (epoch = 20, loss = 1.2370)
Saving model (epoch = 21, loss = 1.2115)
Saving model (epoch = 22, loss = 1.1969)
Saving model (epoch = 24, loss = 1.1566)
Saving model (epoch = 25, loss = 1.1130)
Saving model (epoch = 26, loss = 1.0947)
Saving model (epoch = 28, loss = 1.0822)
Saving model (epoch = 31, loss = 1.0681)
Saving model (epoch = 32, loss = 1.0414)
Saving model (epoch = 33, loss = 1.0325)
Saving model (epoch = 34, loss = 1.0219)
Saving model (epoch = 36, loss = 1.0006)
Saving model (epoch = 42, loss = 0.9903)
Saving model (epoch = 43, loss = 0.9615)
Saving model (epoch = 46, loss = 0.9473)
Saving model (epoch = 48, loss = 0.9305)
Saving model (epoch = 52, loss = 0.9179)
Saving model (epoch = 58, loss = 0.9060)
Saving model (epoch = 61, loss = 0.9049)
Saving model (epoch = 62, loss = 0.8991)
Saving model (epoch = 63, loss = 0.8967)
Saving model (epoch = 67, loss = 0.8928)
Saving model (epoch = 68, loss = 0.8797)
Saving model (epoch = 70, loss = 0.8776)
Saving model (epoch = 73, loss = 0.8588)
Saving model (epoch = 81, loss = 0.8583)
Saving model (epoch = 84, loss = 0.8497)
Saving model (epoch = 86, loss = 0.8392)
Saving model (epoch = 96, loss = 0.8273)
Saving model (epoch = 99, loss = 0.8218)
Saving model (epoch = 105, loss = 0.8191)
Saving model (epoch = 119, loss = 0.8141)
Saving model (epoch = 138, loss = 0.8100)
Saving model (epoch = 139, loss = 0.7944)
Saving model (epoch = 160, loss = 0.7902)
Saving model (epoch = 190, loss = 0.7779)
Saving model (epoch = 218, loss = 0.7770)
Saving model (epoch = 233, loss = 0.7751)
Saving model (epoch = 241, loss = 0.7748)
Saving model (epoch = 270, loss = 0.7630)
Saving model (epoch = 326, loss = 0.7592)
Saving model (epoch = 409, loss = 0.7497)
Saving model (epoch = 541, loss = 0.7488)
Saving model (epoch = 546, loss = 0.7450)
Saving model (epoch = 642, loss = 0.7401)
Saving model (epoch = 670, loss = 0.7389)
Saving model (epoch = 800, loss = 0.7318)
Finished training after 1000 epochs
plot_learning_curve(model_loss_record, title='deep model')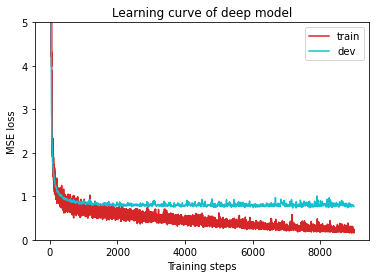
del model
model = SimpleNet(tr_set.dataset.dim)
model.load_state_dict(torch.load(config['save_path'])) # 加载你最好的模型
model.to(device)
plot_pred(dv_set, model, device) # 展示在验证集上的预测结果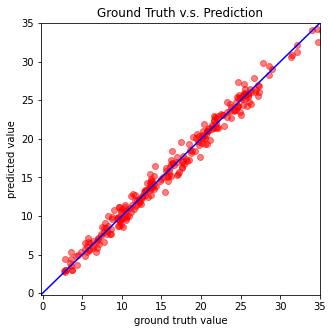
模型测试
在测试集上的结果将会保存到pred.csv文件中
def save_pred(preds, file):
''' 保存预测的结果到指定的文件中 '''
print(f'Saving results to {file}')
with open(file, 'w') as fp:
writer = csv.writer(fp)
writer.writerow(['id', 'tested_positive'])
for i, p in enumerate(preds):
writer.writerow([i, p])
preds = test(tt_set, model, device) # 预测
save_pred(preds, 'pred.csv') # 保存预测结果Saving results to pred.csv



