作业介绍
作业的目标是使用卷积神经网络(我用的是VGG)解决图像分类问题,并用数据扩充的技术提高模型的性能。
使用的数据集是一个关于食物分类的dataset:food-11。如名字所示,食物的种类有11种,分别为面包、乳制品、甜点、鸡蛋、 油炸食品、肉类、面条、米饭、海鲜、汤和水果蔬菜。其中数据分为训练集(9866张)、验证集(3430张)和测试集(3347张),训练集和验证集中照片的格式为”类别_编号.jpg“,如3_100.jpg为类别3(鸡蛋)的照片,测试集中照片的格式为”编号.jpg“,不包含类别,测试集食物的类别需要用模型预测并保存到.csv文件中。
# 导入需要的包
import os
import glob
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import pandas as pd
import numpy as np
import random
from torch.utils.data import Dataset, DataLoader
import time
import matplotlib.pyplot as plt
seed = 2022
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True定义一些函数
def get_device():
''' Get device (if GPU is available, use GPU) '''
return 'cuda' if torch.cuda.is_available() else 'cpu'
def plot_learning_curve(loss_record, title=''):
''' Plot learning curve of your model (train & dev loss) '''
total_steps = len(loss_record['train'])
x_1 = range(total_steps)
x_2 = x_1[::len(loss_record['train']) // len(loss_record['dev'])]
plt.figure(figsize=(6, 4))
plt.plot(x_1, loss_record['train'], c='tab:red', label='train')
plt.plot(x_2, loss_record['dev'], c='tab:cyan', label='dev')
plt.ylim(0.0, 5.)
plt.xlabel('Training steps')
plt.ylabel('MSE loss')
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
def plot_accuracy(acc_record, title=''):
''' Plot accuracy of your model (train & dev acc) '''
total_steps = len(acc_record['train'])
x = range(total_steps)
plt.figure(figsize=(6, 4))
plt.plot(x, acc_record['train'], c='tab:red', label='train')
plt.plot(x, acc_record['dev'], c='tab:cyan', label='dev')
plt.ylim(0.0, 1.)
plt.xlabel('Training epochs')
plt.ylabel('accuracy')
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
def plot_pred(preds, root):
# 只画前16张图片的预测结果
text = {0:'面包', 1:'乳制品', 2:'甜点', 3:'鸡蛋', 4:'油炸食品',
5:'肉类', 6:'面条', 7:'米饭', 8:'海鲜', 9:'汤',10:'水果蔬菜'}
fnames = glob.glob(os.path.join(root, '*'))
# 设置子图数量和画布大小
plt.figure(num=16,figsize=(20,20))
# 设置显示中文字体(黑体)
plt.rcParams['font.family'] = ['SimHei']
for i in range(16):
# 4行4列的第i+1个子图
plt.subplot(4,4,i+1)
img = plt.imread(fnames[i])
plt.imshow(img)
label = preds[i]
# 在图片(70,120)的位置标出食物类别(是否戴眼镜),字体大小为 24,字体颜色为红色
plt.text(x=70, y=120, s=text[label], fontdict={'fontsize':48 ,'color':'red'})
plt.xticks([])
plt.yticks([])数据预处理
Dataset
class FoodDataset(Dataset):
''' 制作Dataset '''
def __init__(self, fnames, mode, transform):
self.fnames = fnames
self.mode = mode
self.transform = transform
print(f'Finished reading the {mode} set({len(fnames)} samples found)')
def __len__(self):
return len(self.fnames)
def __getitem__(self, idx):
fname = self.fnames[idx]
fname = fname.replace('\\', '/')
# 加载图片
img = torchvision.io.read_image(fname)
# transform
img = self.transform(img)
if self.mode == 'test':
return img
else:
label = [int(fname.split("/")[-1].split("_")[0])]
label = torch.LongTensor(label)
label = label.squeeze()
return img, labelDataLoader
def pre_dataloader(root, mode, transform, batch_size):
''' 制作DataLoader '''
fnames = glob.glob(os.path.join(root, '*')) # 获取当前路径下的所有文件对应的路径
dataset = FoodDataset(fnames, mode, transform) # 生成一个数据集,并输入到指定的dataloader
dataloader = DataLoader(
dataset, batch_size,
shuffle = (mode == 'train'))
return dataloader模型实现
模型构建
这部分主要自己实现一个VGG网络结构,在这之前我们简单的讲解一下VGG的结构。
VGG网络主要由两个部分组成:第一部分主要是卷积层和池化层组成,第二部分由全连接层组成。它的特点如下:
- 每个卷积层中使用3x3filters,并将它们组合成卷积序列
- 多个3x3卷积序列可以模拟更大的接受场的效果
- 每次的图像像素缩小一倍,卷积核的数量增加一倍
VGG有很多个版本,也算是比较稳定和经典的model。它的特点也是连续conv多计算量巨大,这里我们以VGG16为例
其中,VGG清一色用小卷积核的优势有:
- 3层conv3x3后等同于1层conv7x7的结果; 2层conv3x3后等同于2层conv5x5的结果
- 卷积层的参数减少。相比5x5、7x7和11x11的大卷积核,3x3明显地减少了参数量
- 通过卷积和池化层后,图像的分辨率降低为原来的一半,但是图像的特征增加一倍,这是一个十分规整的操作,为后面的网络提供了一个标准
下面我们根据VGG16的特点来实现这个模型:
import torch
from torch import nn
VGG16 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(25088, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 1000))由于我电脑跑不动这个模型,所以在它的基础上进行稍微的修改,本文用的模型如下:
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
# torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
# torch.nn.MaxPool2d(kernel_size, stride, padding)
# input 维度 [3, 128, 128]
self.cnn = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1), # [64, 128, 128]
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [64, 64, 64]
nn.Conv2d(64, 128, 3, 1, 1), # [128, 64, 64]
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [128, 32, 32]
nn.Conv2d(128, 256, 3, 1, 1), # [256, 32, 32]
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [256, 16, 16]
nn.Conv2d(256, 512, 3, 1, 1), # [512, 16, 16]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 8, 8]
nn.Conv2d(512, 512, 3, 1, 1), # [512, 8, 8]
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2, 2, 0), # [512, 4, 4]
)
self.fc = nn.Sequential(
nn.Linear(512 * 4 * 4, 1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.ReLU(),
nn.Linear(512, 11)
)
def forward(self, x):
out = self.cnn(x)
out = out.view(out.size()[0], -1)
return self.fc(out)模型训练
def train(tr_set, dv_set, model, config, device):
''' 训练模型 '''
n_epochs = config['n_epochs'] # 最大迭代次数
optimizer = torch.optim.Adam(model.parameters(), lr=config['lr']) # optimizer使用Adam
criterion = nn.CrossEntropyLoss() # 损失函数使用CrossEntropyLoss
min_loss = 1000 # 用于记录验证时最小的loss
loss_record = {'train': [], 'dev': []} # 记录训练损失
acc_record = {'train': [], 'dev': []} # 记录预测准确度
for epoch in range(n_epochs):
start_time = time.time()
train_acc, train_loss = 0.0, 0.0
model.train() # 调整为train模型(开放Dropout等等)
for i, data in enumerate(tr_set):
optimizer.zero_grad() # 将模型参数的 gradient 至0
pred = model(data[0].to(device)) # 前向传播
loss = criterion(pred, data[1].to(device)) # 计算loss
loss.backward() # 利用后向传播算出每个参数的gradient
optimizer.step() # 更新模型参数
train_acc += np.sum(np.argmax(pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += loss.detach().cpu().item() * len(data)
loss_record['train'].append(loss.detach().cpu().item())
train_acc /= len(tr_set.dataset)
train_loss /= len(tr_set.dataset)
acc_record['train'].append(train_acc)
# 每次迭代后,在验证集中验证你的模型
dev_acc, dev_loss = dev(dv_set, model, device, criterion)
acc_record['dev'].append(dev_acc)
loss_record['dev'].append(dev_loss)
# 将结果打印出来
print('[%02d/%02d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \
(epoch + 1, n_epochs, time.time() - start_time, train_acc, train_loss, dev_acc, dev_loss))
# 当模型性能提升时保存模型
if dev_loss < min_loss:
min_loss = dev_loss
print(f'Saving model (epoch = {epoch+1:02d}, loss = {min_loss:.4f})')
torch.save(model.state_dict(), config['save_path']) # 保存模型到指定路径
return min_loss, loss_record, acc_record模型验证
def dev(dv_set, model, device, criterion):
model.eval()
dev_loss, dev_acc = 0, 0
for i, data in enumerate(dv_set):
with torch.no_grad():
pred = model(data[0].to(device)) # 前向传播
loss = criterion(pred, data[1].to(device)) # 计算loss
dev_acc += np.sum(np.argmax(pred.cpu().data.numpy(), axis=1) == data[1].numpy())
dev_loss += loss.detach().cpu().item() * len(data)
dev_acc /= len(dv_set.dataset)
dev_loss /= len(dv_set.dataset)
return dev_acc, dev_loss模型测试
def test(tt_set, model, device):
model.eval()
preds = []
for x in tt_set:
x = x.to(device)
with torch.no_grad():
pred = model(x)
pred = np.argmax(pred.cpu().data.numpy(), axis=1)
for y in pred:
preds.append(y)
return preds设置超参数
config中包含模型训练的超参数(可以进行调节)和保存模型的路径
device = get_device()
os.makedirs('models', exist_ok=True)
data_dir = './food-11'
# 可以进行调节来提升模型性能
config = {
'n_epochs': 30, # 最大迭代次数
'batch_size': 128, # dataloader的最小批量
'lr': 0.001,
'save_path': 'models/model.pth' # 模型保存路径
}加载数据和模型
这部分需要注意的是我们需要为不同的数据制定不同的transform,因为我们只能对训练数据做数据扩充
# 训练时做数据扩充
train_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((128,128)),
transforms.RandomHorizontalFlip(), # 随机将图片水平翻转
transforms.RandomRotation(15), # 随机旋转图片
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
])
# 验证测试时不用做数据扩充
test_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((128,128)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
])
tr_set = pre_dataloader(os.path.join(data_dir,'training'), 'train', train_transform, config['batch_size'])
dv_set = pre_dataloader(os.path.join(data_dir,'validation'), 'dev', test_transform, config['batch_size'])
tt_set = pre_dataloader(os.path.join(data_dir,'testing'), 'test', test_transform, config['batch_size'])Finished reading the train set(9866 samples found)
Finished reading the dev set(3430 samples found)
Finished reading the test set(3347 samples found)
展示16张训练集的图片
images= [(tr_set.dataset[i][0]+1)/2 for i in range(16)]
grid_img = torchvision.utils.make_grid(images, nrow=8)
plt.figure(figsize=(10,10))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show() 
model = Classifier().to(device)开始训练
min_loss, loss_record, acc_record = train(tr_set, dv_set, model, config, device)[01/30] 86.74 sec(s) Train Acc: 0.218123 Loss: 0.036563 | Val Acc: 0.262974 loss: 0.032123
Saving model (epoch = 01, loss = 0.0321)
[02/30] 83.66 sec(s) Train Acc: 0.311372 Loss: 0.030771 | Val Acc: 0.322449 loss: 0.030530
Saving model (epoch = 02, loss = 0.0305)
[03/30] 83.76 sec(s) Train Acc: 0.369349 Loss: 0.028417 | Val Acc: 0.406122 loss: 0.026898
Saving model (epoch = 03, loss = 0.0269)
[04/30] 86.88 sec(s) Train Acc: 0.414454 Loss: 0.026027 | Val Acc: 0.411079 loss: 0.025972
Saving model (epoch = 04, loss = 0.0260)
[05/30] 85.10 sec(s) Train Acc: 0.467971 Loss: 0.023721 | Val Acc: 0.383382 loss: 0.030133
[06/30] 84.83 sec(s) Train Acc: 0.507399 Loss: 0.022244 | Val Acc: 0.367055 loss: 0.033233
[07/30] 87.24 sec(s) Train Acc: 0.532840 Loss: 0.020973 | Val Acc: 0.514286 loss: 0.023898
Saving model (epoch = 07, loss = 0.0239)
[08/30] 86.20 sec(s) Train Acc: 0.577944 Loss: 0.019479 | Val Acc: 0.502332 loss: 0.023984
[09/30] 88.35 sec(s) Train Acc: 0.591222 Loss: 0.018706 | Val Acc: 0.563848 loss: 0.020785
Saving model (epoch = 09, loss = 0.0208)
[10/30] 85.91 sec(s) Train Acc: 0.621528 Loss: 0.017443 | Val Acc: 0.557143 loss: 0.021090
[11/30] 86.38 sec(s) Train Acc: 0.616562 Loss: 0.017344 | Val Acc: 0.560641 loss: 0.020721
Saving model (epoch = 11, loss = 0.0207)
[12/30] 87.27 sec(s) Train Acc: 0.648490 Loss: 0.016085 | Val Acc: 0.565015 loss: 0.020585
Saving model (epoch = 12, loss = 0.0206)
[13/30] 86.36 sec(s) Train Acc: 0.662376 Loss: 0.015385 | Val Acc: 0.609621 loss: 0.018134
Saving model (epoch = 13, loss = 0.0181)
[14/30] 87.04 sec(s) Train Acc: 0.672816 Loss: 0.014737 | Val Acc: 0.576676 loss: 0.020833
[15/30] 86.98 sec(s) Train Acc: 0.691871 Loss: 0.013995 | Val Acc: 0.547230 loss: 0.023204
[16/30] 86.17 sec(s) Train Acc: 0.701297 Loss: 0.013776 | Val Acc: 0.516618 loss: 0.024357
[17/30] 87.39 sec(s) Train Acc: 0.713866 Loss: 0.012795 | Val Acc: 0.627697 loss: 0.017918
Saving model (epoch = 17, loss = 0.0179)
[18/30] 87.07 sec(s) Train Acc: 0.733732 Loss: 0.012115 | Val Acc: 0.628280 loss: 0.018558
[19/30] 87.39 sec(s) Train Acc: 0.735962 Loss: 0.011708 | Val Acc: 0.623907 loss: 0.019147
[20/30] 86.86 sec(s) Train Acc: 0.761200 Loss: 0.010815 | Val Acc: 0.639650 loss: 0.019255
[21/30] 87.09 sec(s) Train Acc: 0.779749 Loss: 0.009971 | Val Acc: 0.608455 loss: 0.021485
[22/30] 87.64 sec(s) Train Acc: 0.772045 Loss: 0.010318 | Val Acc: 0.633528 loss: 0.019861
[23/30] 86.32 sec(s) Train Acc: 0.777215 Loss: 0.009820 | Val Acc: 0.661808 loss: 0.018393
[24/30] 87.13 sec(s) Train Acc: 0.810562 Loss: 0.008549 | Val Acc: 0.647230 loss: 0.019221
[25/30] 86.26 sec(s) Train Acc: 0.799818 Loss: 0.009009 | Val Acc: 0.655394 loss: 0.019204
[26/30] 84.89 sec(s) Train Acc: 0.839955 Loss: 0.007461 | Val Acc: 0.650437 loss: 0.018734
[27/30] 88.26 sec(s) Train Acc: 0.839955 Loss: 0.007236 | Val Acc: 0.641399 loss: 0.020359
[28/30] 90.81 sec(s) Train Acc: 0.846544 Loss: 0.007010 | Val Acc: 0.643149 loss: 0.020707
[29/30] 85.49 sec(s) Train Acc: 0.851105 Loss: 0.006651 | Val Acc: 0.650146 loss: 0.022475
[30/30] 86.92 sec(s) Train Acc: 0.871883 Loss: 0.005801 | Val Acc: 0.667055 loss: 0.021603
plot_accuracy(acc_record, title='cnn model')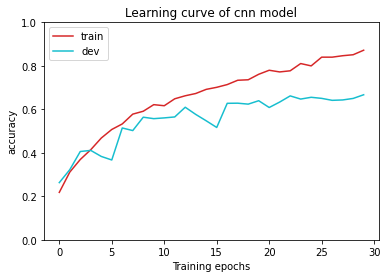
模型测试
加载最优模型预测测试集上的结果
del model
model = Classifier()
model.load_state_dict(torch.load(config['save_path'])) # 加载你最好的模型
model.to(device)
preds = test(tt_set, model, device)展示部分预测结果
plot_pred(preds, os.path.join(data_dir,'testing'))
在测试集上的结果将会保存到pred.csv文件中
with open("predict.csv", 'w') as f:
f.write('Id,Category\n')
for i, y in enumerate(preds):
f.write('{},{}\n'.format(i, y))


