前言
对抗攻击英文为adversarial attack,即对输入样本添加一些人无法察觉的细微改动,导致模型以高置信度输出一个错误的答案。在现实生活中,我们建立的系统很多时候会遇到干扰,甚至是人为的蓄意攻击,如垃圾邮件、恶意软件和网络入侵等。因此机器训练出来的模型不光性能要好,还要能够对抗人类的恶意,这就是对抗攻击与防御产生的动机。
对抗攻击
例子
以图片攻击为例,图片可以看成一个很长的向量,如果在一些重要的像素部分加上一个很小的杂讯,再把它输入到神经网络。虽然我们人眼识别不出来这个改动,但通过深度学习训练出来的分类可能就会误判。下图只是为了直观,但在实际应用中这种攻击人眼是识别不出来的。
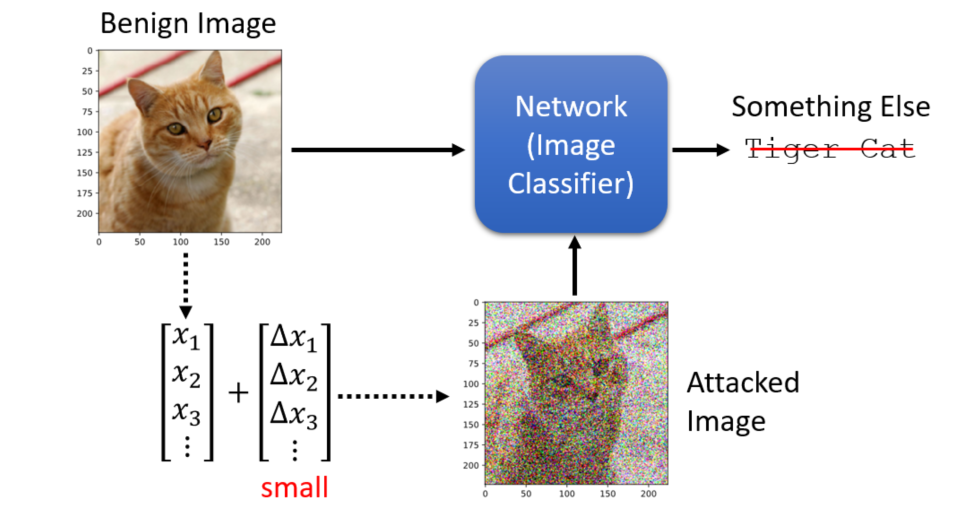
通常没有被攻击的图片称为Benign Image,被攻击的图片称为Attacked Image。按照攻击得到的类别,对抗攻击可以分为:
- 定向攻击(targeted attack):误分类成一个指定的类别
- 非定向攻击(non-targeted attack):误分类成其他类别(只要不是正确的类别即可)
数学理论
假设benign image是$x^{0}$,输入到一个图像分类器中,输出为$y^{0}=f(x^{0})$,该图片对应的真实分类为cat,$\overset{-}{y}$
被攻击后的输入是x,输出$y=f(x)$,想要攻击成功的话,就得让y和$\overset{-}{y}$相差越大越好。如果是定向攻击的话,还要保证y和$y^{target}$越接近越好。
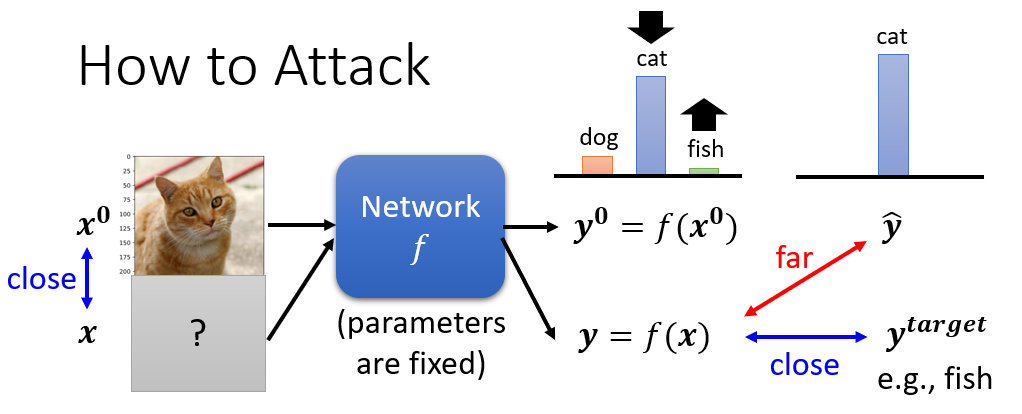
因此这个模型的损失函数(Loss Function)可以定义为:
- Non-targeted attack: $L(x)=-e(y,\overset{-}{y})$
- targeted attack: $L(x)=-e(y,\overset{-}{y})+e(y,y^{target})$
式中函数e()表示输入之间的差异,目标是使L(x)越小越好
另外正如我们前面所说,这些攻击是不容易被人类观察到的,即$x$和$x^{0}$之间的差距越小越好,所有整个模型需要优化的表达式为:
$$x^{*}=arg \underset{d(x,x^{0})\leq\epsilon}{min}L(x)$$
怎么计算$d(x,x^{0})$呢,通常采用的是向量p-范数
2-范数L2-norm :$d(x,x^{0})=\parallel \Delta x \parallel_{2} = \sqrt{\overset{n}{\underset{i=1}{\sum}}|\Delta x_{i}|^{2}}$
无穷范数L-infinity :$d(x,x^{0})=\parallel \Delta x \parallel_{\infty} = \underset{i}{max}|\Delta x_{i}|$
确定后模型的损失函数后,我们就可以用其来确定输入,这与往常的神经网络更新网络结构的参数是不一样的,因为被攻击的模型已经确认。
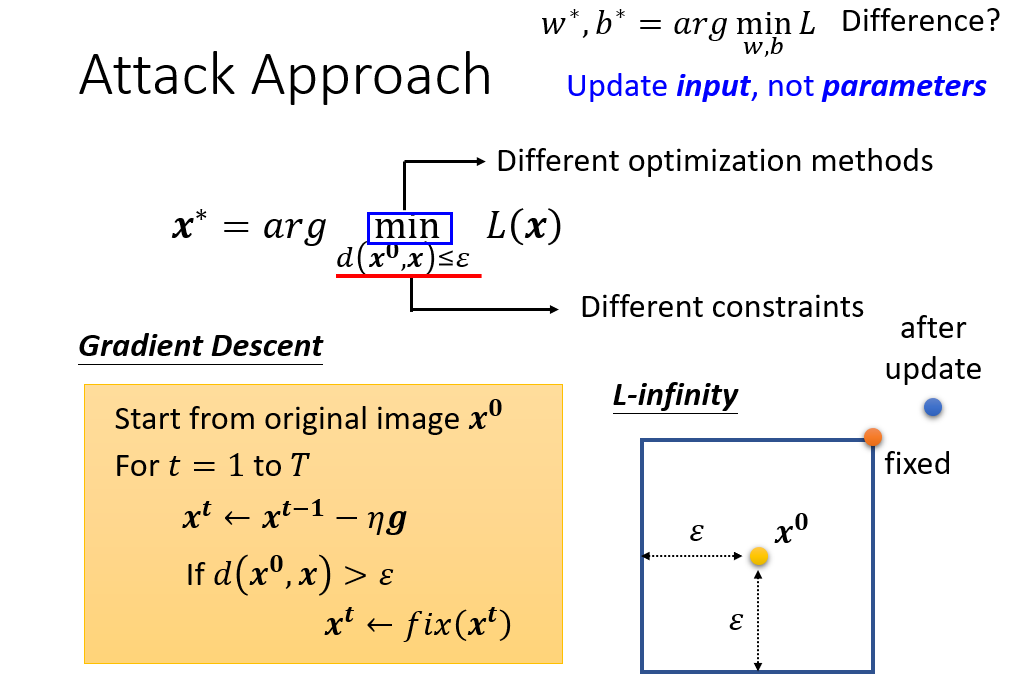
同样,我们可以采用梯度下降法确定输入x,因为模型对输入加了限制,因此我们需对优化算法进行一些修改。以L-infinity确认$d(x,x^{0})$,则为了满足$d(x,x^{0})\leq\epsilon$的限制,只需将每个像素的的更新都在以$\epsilon$为边长的正方形内。
从整个数学理论上看,如果我们想对攻击进行改进,就需要使用更有效的限制或者更好的优化方法。
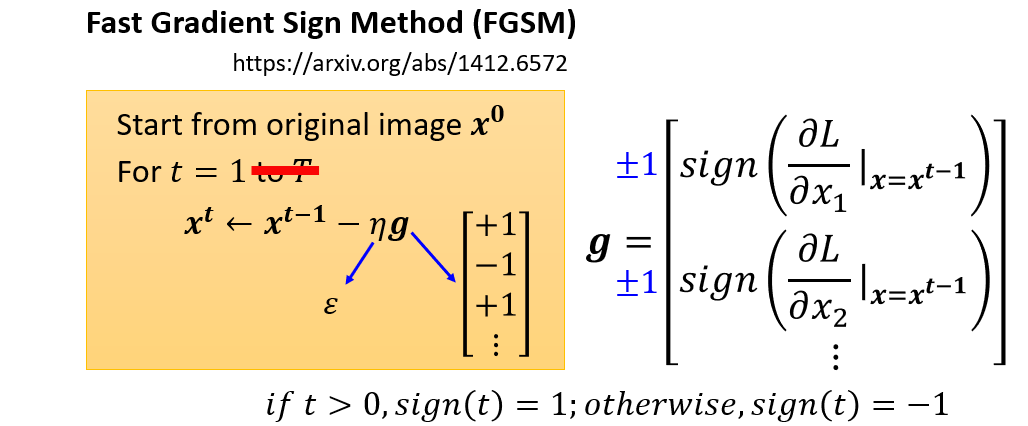
李宏毅老师课堂上了讲解了两种优化方法,下面提供了论文的链接,感兴趣的可以去了解一下
FGSM中作者的想法很大胆,只使用一次迭代就可以达到攻击的目的。作者只是对上面的方法做了一个简单的修改,在对损失函数求导得到的梯度上加一个符号函数sign(大于0输出1,小于0输出-1),这样就能满足输入限制的要求
白盒攻击&黑盒攻击
前面我们列举的例子就是白盒攻击(white box attack),即在攻击之前我们就已经知道模型的参数。但在通常情况下,我们是不知道模型的参数,这种情况下的攻击被称作黑盒攻击(black box attack)。
黑盒攻击
- 不知道目标模型的参数,但有目标模型的训练资料
在这种情况之下,我们可以训练一个替代模型,然后使用代理模型产生被攻击的对象
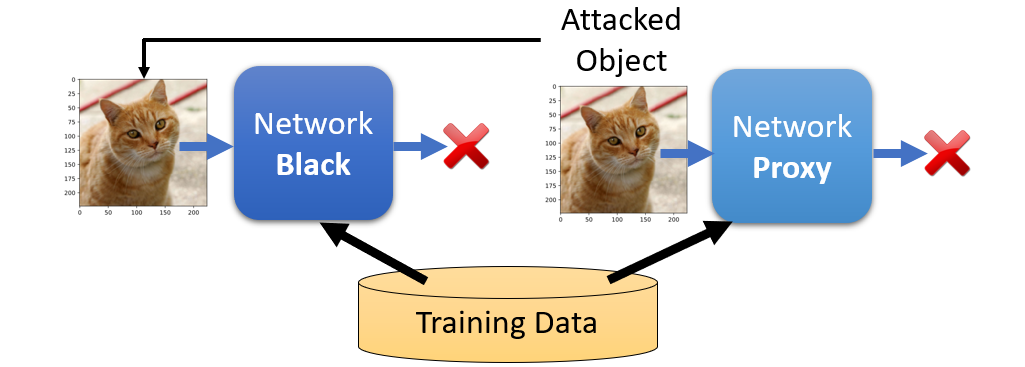
那么上面所说的黑箱攻击容易成功吗?
从论文Delving into Transferable Adversarial Examples and Black-box Attacks的实验结果来看,是容易成功的
下图中有两个表格,第一个表格中列代表被攻击的模型,行代表的是代理模型。每个单元格中的数值表示在行中模型生成攻击成功的图像在列中模型上评估的正确性。因此准确率越低,代表产生的攻击越有效。对角线上代理模型和攻击模型是同一模型,可以看成是白盒攻击。不同行不同列即为黑盒攻击,从实验结果中可以看出得出的准确率都在50%以下,因此黑箱攻击还是挺有效。
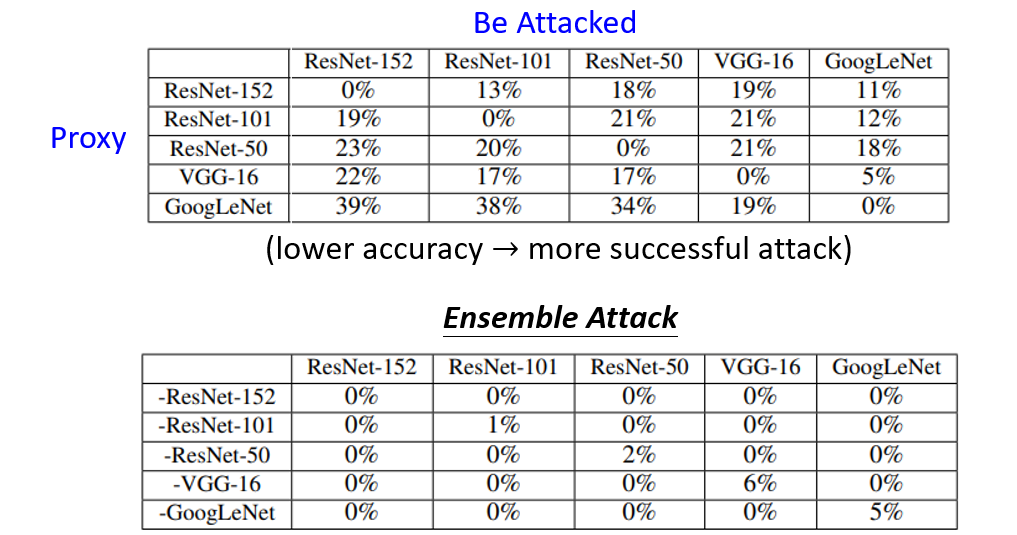
第二个表格中“-”好代表没有用这个模型训练生成攻击成功的图像,因此在第二个表格中,对角线代表的是黑盒攻击,因为代理模型中并未采用待攻击的模型。这些黑盒攻击中,准确率最高为6%,比第一个表格中只使用一个代理模型产生的黑盒攻击的模型准确率降了很多,说明采用多个代理模型产生的黑盒攻击更有效。
你可能还是会怀疑黑盒攻击为什么会产生效果,这篇论文作者给出的j解释是每个模型产生攻击的方向很相似,想更深入了解这个问题可以看论文Adversarial Examples Are Not Bugs, They Are Features
另外还有很多黑盒攻击:
- One Pixel Attack for Fooling Deep Neural Networks,只需要改变一个像素就可以达到攻击的目的
- Universal adversarial perturbations,使用一个通用的非常小的扰动就可以让攻击成功
上面讲述的对抗攻击都是应用在图像上,其实对抗攻击还可以应用于语言处理、自然语言处理以及我们的日常生活中,因此我们需要想办法做好防御,来抵御这些来自人类的恶意。
防御
防御有以下两种:被动防御和主动防御
被动防御
以图像攻击为例,被动防御中最经典的做法就是在图像进入模型之前在一个filter(滤波器),这样会使那些使得攻击成功的扰动信号失真,从而使攻击失效。
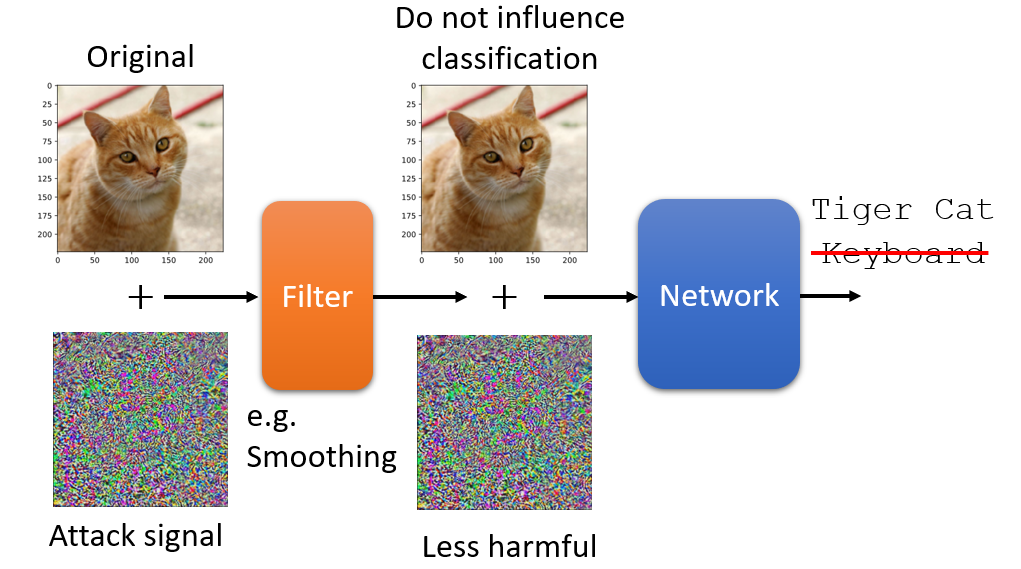
常用的方法有:
- 将输入图像轻微模糊化,但并不影响分类
- 图像压缩(先压缩再解压从而消除攻击)
- 使用Generator技术生成和输入图像几乎一摸一样的image
- 随机防御(Randomization),有几种防御手段,随机选择其中一个,目的是预防防御预先被人知道
主动防御
主动防御为每一张图像生成一个对抗图像,然后将生成的对抗图像和原始图像都丢入模型中进行训练(对抗训练),从而增强了模型的鲁棒性。这种方法也可以看作一种数据增强(Data Augmentation)的手段,缺点就是成倍的增加计算量。
参考资料
[1] 李宏毅2021机器学习课程



