引言
我们都知道神经网络是一个黑箱模型,虽然它在测试集的准确率可以达到很高,但很难解释清楚其中缘由。而有些模型像线性模型、决策树等虽然很容易解释,但模型往往不够强大,在测试集上有很差的表现。然而,在测试集上表现好并不意味着模型很智能,在一些领域中,我们不但需要模型的性能好,还需要知道为什么,我们才会放心的使用这个模型。如当我们用ML挑选简历时,我们需要知道机器学习模型是依据应聘人的那些特征做出推荐的决定,而不单单是该模型在测试集中表现好。
可解释性人工智能(Explainable AI)这个技术可以用于填补这个鸿沟,但可解释性并不意味着我们要完全明白ML模型是如何运作的,就像我们不完全知道人类的大脑运行的原理,但是我们相信人类做出的决定。我们需要的只是ML模型给我一个它做出决定的理由,而这个理由可以被我们和我们的顾客以及老板满意。
种类
机器学习的可解释性包括两个方面,一个是local explanation,另一个是global explanation。以图像分类器为例,local explanation需要回答的是为什么你觉得这张图片属于这个类别?而global explanation需要回答的是这些类别具有什么样的特征?
Local explanation
仍然以图像分类器为例,Local explanation的目标是每个component对于最终结果的重要性程度,这可以通过移动或修改其中一个component来看模型输出的变化来实现,模型输出改变越大,意味着这个component越重要。
基于梯度的方法
假设输入为一张图像$x$,它有很多component ${x_{1},x_{2},…,x_{N}}$ 组成。如果输入是image,则component一般是pixel,segment等。如果输入是text,则component一般是word。现在我们依次给每个component加上一个$\Delta x$,对应就会得到一个loss $\Delta e$(模型输出和真实值之间)。我们想要知道每个component对于模型判断的重要性,只需计算对应的$|\frac{\Delta e}{\Delta x}|=|\frac{\partial e}{\partial x_{n}}|$得到。利用这些数值,我们可以绘制saliency map,如下图,亮度越高(即前面计算的数值越大)的区域代表这个component对于预测结果的影响越大

基于梯度来判断component重要性的方法也存在局限性:Noisy Gradient和Gradient Saturation
Noisy Gradient是有些梯度会非常大(如下图),我们可以通过在计算梯度时添加多个扰动,然后计算加入扰动后的平均梯度避免,这种方法被称作SmoothGrad,相关见论文Randomly add noises to the input image, get saliency maps of the noisy images, and average them

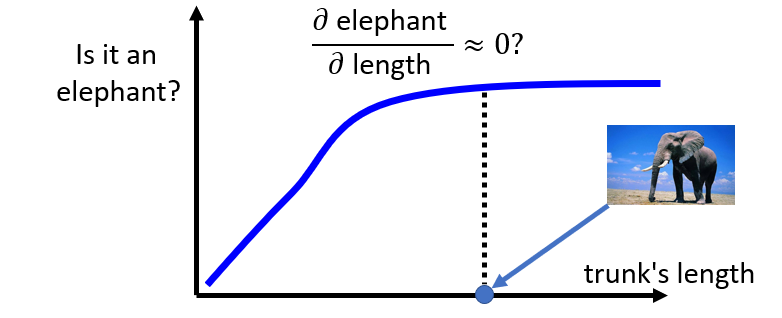
Gradient Saturation是指某个因素对图片的预测起到了推动作用,但是这个作用是有限的,超过一定程度后就不再增加预测的几率。以预测大象这个类别为例,很明显鼻子的长度是一个很重要的影响因素。随着鼻子长度的增加,预测的几率的几率会增加,但超过一定数值后,预测概率不会增加,即出现变化率为0的情况,但这个鼻子长度的动物已经不能算是大象了。
Global explanation
假设我们已经训练好一个CNN网络结构,将一张图片X输入CNN,在每一个filter后提取一个feature map,每个feature map都有对应的特征值$a_{ij}$,我们可以通过使这些特征值之和最大为目标找到对应的输入X,通过观察这个输入的特征我们就可以判断这个filter可以侦察到图片的某些特征。或者我们可以以输出为目标,找到输出为某种类别概率最高对应的输入X即可得到该类别图片对应有哪些特征?
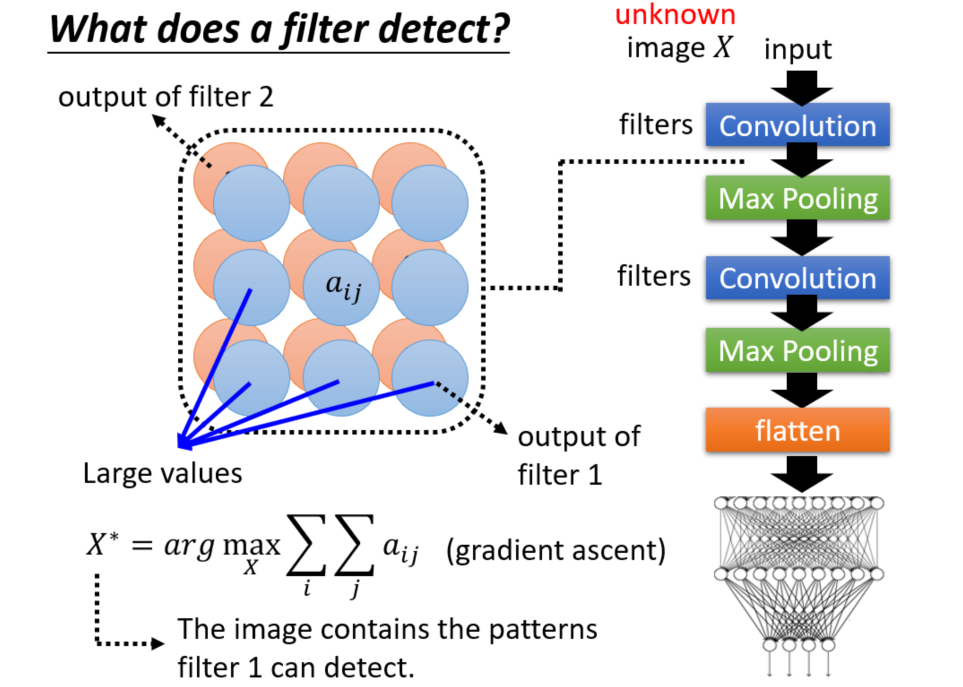
但事实上,我们更多时候我们找到的X是一堆杂讯,我们根本不能从中学习到什么?其中一个解决方法是在优化目标上加上一个限制R(X),R(X)应符合图案本身的设计,同时你还需调影响结果的超参数。下面展示Understanding Neural Networks Through Deep Visualization侦察到各种类别对应的图片特征。

另外还有一种更有效的方式,利用Generator。利用GAN训练一个Image Generator,可以通过低维度的向量通过Generator得到一个图片。与前面通过对应某个类别概率最大找到模型对应输入X不同的是,这里我们找到对应的输入z,然后将这个z输入Generator中得到Image X。借助这个图片,我们就可以找出该类别具有的一些特征。
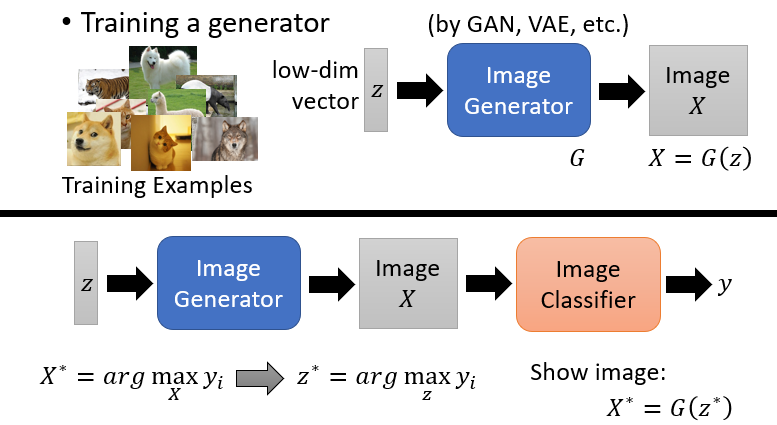
推荐论文:Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space
参考资料
[1] 李宏毅2021机器学习课程



