今天学习一篇ASR-语言识别领域的文章,来自google的:

引言
提到端到端自动语音识别(ASR)系统,你可能会想到循环神经网络(RNN),因为RNN可以有效地模拟音频序列中的时间依赖性;你可能也会想到基于self-attention的Transformer架构,因为它能够捕捉序列的整体特征并且训练效率高;你甚至会想到卷积神经网络(CNN),因为它可以通过逐层捕捉序列的局部特征而获得序列的特征。
然而,基于self-attention或者卷积的模型都有它们的缺点。Transformer在提取长序列依赖的时候很有效,但它不擅长提取序列的局部特征,而卷积神经网络恰好相反。因此有没有可能将这两种特性结合起来建立一个新的模型,这个模型能同时提取输入数据的局部特征和整体特征。
Conformer就是将这两者结合起来,用卷积增强的Transformer做语音识别,并取得杰出的效果。下面,我们来学习一下Conformer的机制。
Conformer
语音识别使用的也是一个seq2seq模型,Conformer只使用卷积来改变encoder部分。Conformer Encoder的总体架构如下,首先我们用convolution subsampling layer处理输入,然后通过多个conformer blocks。
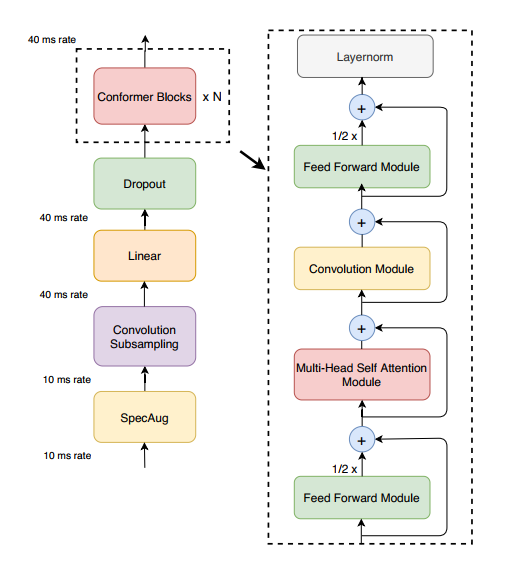
其中conformer blocks是由Feedforward module,Multi-head self attention Module, Convolution Module这三个Module组成的,其中Feedforward module在前后都有使用。下面我们分别学习这三个Module,并学习这些Moudle是如何结合在一起的。
Multi-Headed Self-Attention Module
该Moudle采用了多头自注意力机制(multi-headed self-attention, MHSA),同时结合了Transformer-XL的一个重要技术——相对正弦位置编码方案。相对正弦位置编码使得self-attention module在不同的输入长度上具有更好的泛化能力,并且加强了编码器的鲁棒能力。同时该Moudle还使用了带有dropout的prenorm残差单元,这有助于训练和规范更深层次的模型。其整体结构如下图所示:

Convolution Module
对于Convolution Module,使用了prenorm残差,pointwise卷积和线性门单元(Gated Linear Unit, GLU),随后又经过了一系列结构,如下图所示:

Feed Forward Module
对于Feed Forward Module,使用lprenorm残差,紧接着通过一个线性层和Swish激活函数,然后通过另一个线性层,该线性层前后都经过dropout处理,如下图所示:

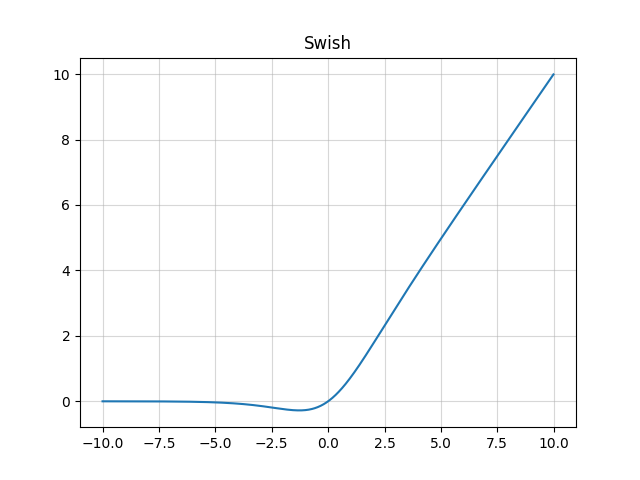
从Convolution Module和Feed Forward Module来看,它们都使用了Swish激活函数,它的计算公式如下
$$f(x)=x*\sigma(x)$$
式中,$\sigma(x)=(1+exp(-x))^{-1}$,它是一个sigmoid函数,有关它的图像如下图所示:
Conformer Block
再回顾Conformer Block,我们可以得到它的计算公式:
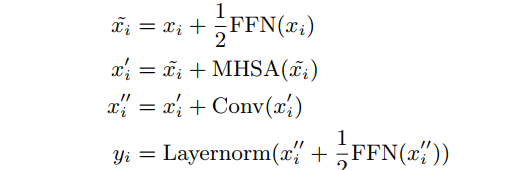
其中FFN是Feed Forward Module,MHSA是Multi-Headed Self-Attention Module,Conv是Convolution Module。其中特别注意这里使用的是1/2FFN,作者文中说明了半个要比一个的效果好。
实验
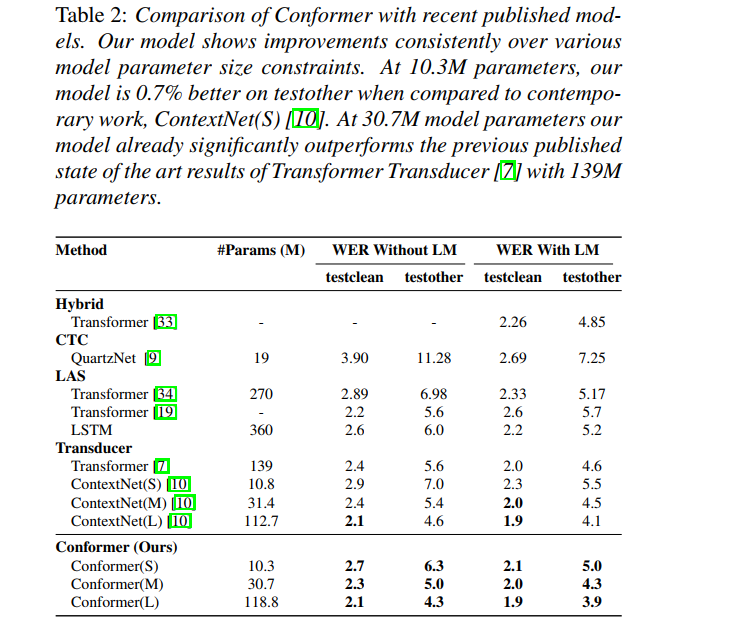
这部分就简单介绍一下,数据采用的是librispeech数据,其中包括970小时的labeled speech和额外的800M单词标记的文本语料库,用于构建语言模型。为了比较不同配置的Encoder好坏,统一使用单层的LSTM作为Decoder
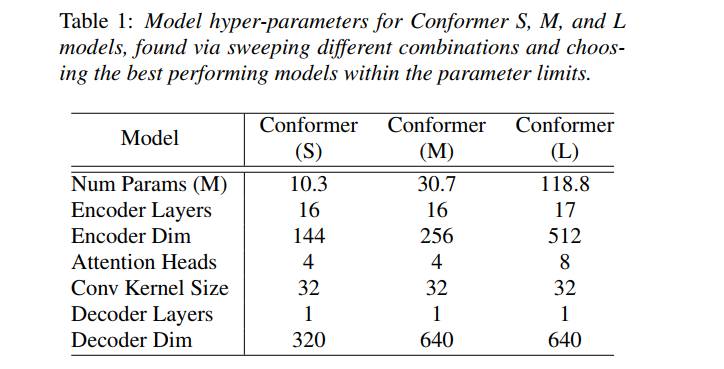
实验中三种不同规模的Conformer的参数配置如下:
表格2展示的是和其他模型的对比情况,Conformer都达到了较好的效果
同时作者还探讨了各个模块以及每个模块参数以及模块中结构的顺序对模型的影响,在这就不多加叙述,想了解的可以看原文。



