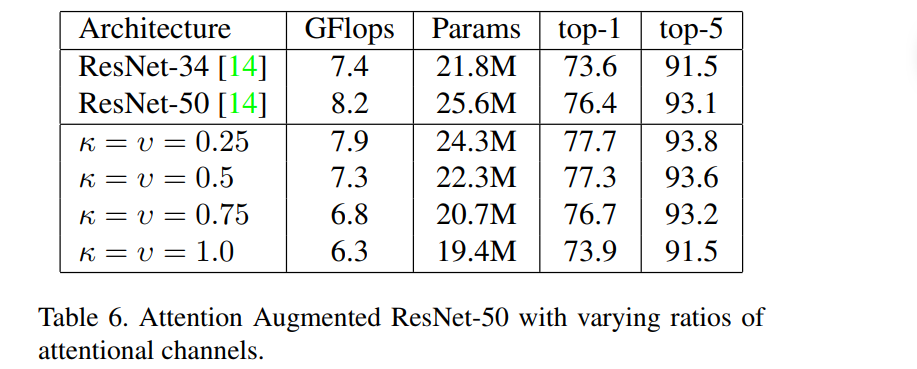
主要思想:作者将卷积得到的特征图与通过自注意力机制产生的一组特征图连接(concatenate)起来,通过这种自注意力机制来增强卷积算子,从而提升模型性能。
前言
卷积神经网络(CNN)在许多计算机视觉应用中都取得了巨大的成功,特别是在图像分类中。然而,CNN有一个显著的弱点,由于卷积操作和池化操作,只对图像的局部领域进行操作,因此缺少全局信息,而这些信息对于图像识别是很有必要的。
而在捕获长距离交互关系(long range interaction),自注意力的表现不错。自主意力背后的关键思想是生成隐藏层计算的值的加权平均值。不同于卷积操作或者池化操作,这些权重是动态根据输入特征,通过隐藏单元之间的相似函数产生的。因此,输入信号之间的交互互动只依赖于信号本身,不像卷积,由它们的相对位置事先决定。
因此,本文将自主意力计算应用到卷积操作中,实现了长距离交互。同时本文考虑使用自主意力替代卷积做判别性视觉任务,提出了二维相关自主意力机制(two-dimensional relative self-attention mechanism),并在此基础上注入相对位置信息,使其更加适合用于图像处理。本文实验表明,上述机制在完全替代卷积方面具有很大的竞争力,但实验中发现将两者结合可以获得更好的结果。因此作者并没有完全抛弃卷积,而是利用自主意力来增强卷积,即将强调局部特征的卷积特征图和能够获取长距离依赖的自主意力特征图拼接起来得到最终结果。
方法
在介绍本文方法之前,我们先来了解注意力增强的卷积网络的主要结构:
- H,W,$F_{in}$:输入特征图的height,weight,通道数量
- $N_{h}$,$d_{v}$,$d_{k}$:heads的数量,values的深度,queries和keys的深度(多头注意力中的一些参数)。这里$d_{v}、d_{k}$必须可以被$N_{h}$整除,并且$d_{v}^{h}、d_{k}^{h}$为每个head中values、queries和keys的深度
图像中自主意力的计算
和注意力的计算一样,只不过需要对图像输入数据做一定的处理——输入tensor$(H,W,F_{in})$flatten成矩阵$X\in R^{HW\times F_{in}}$作为输入。
单头的计算形式:
$$O_{h}=Softmax(\frac{(XW_{q})(XW_{k})^{T}}{\sqrt{d_{k}^{h}}})(XW_{v})$$
多头的计算形式:
$$MHA(X)=Concat(O_{1},…,O_{Nh})W^{O}$$
相关公式推导可以看前面笔记自注意力模型
二维位置编码
由于自主意力没有利用位置信息,因此满足交换律:$MHA(\pi (X))=\pi(MHA(X))$。
这里的$\pi$表示像素位置的任意交换,所以自主意力对于模拟像图像这种高度结构化的数据不是很有效,这时位置编码的技术就很关键。
- the Image Transformer extends the sinusoidal waves first introduced in the original Transformer to 2 dimensional inputs
- CoordConv concatenates positional channels to an activation map
然而,这些位置编码技术并不适合图像分类和目标检测。作者将其归因于这些技术虽然可以打破置换等变性(permutation equivariant),但不能处理图像任务时需要的平移等变性(translation equivariance)。而相对位置编码在打破置换等变性的同时实现了平移等变性,本文在相对位置编码的理论基础上将其拓展到二维上,并且基于Music Transformer提出一个内存有效实施的方法。
相对位置编码(Relative positional encodings)
本文通过相对位置编码技术注入了图像的相对高度和宽度信息,从而弥补了图像自主意力计算的缺点。则像素$i=(i_{x},i_{y})$关于像素$j=(j_{x},j_{y})$的attention logit计算公式如下:
$$l_{i,j}=\frac{q_{i}^{T}}{\sqrt{d_{k}^{h}}}(k_{j}+r_{j_{x}-i_{x}}^{W}+r_{j_{y}-i_{y}}^{H})$$
- $q_{i}$是像素i对应的查询向量,即矩阵Q的第i行
- $k_{j}$是像素j对应的键向量,即矩阵K的第j行
- $r_{j_{x}-i_{x}}^{W}、r_{j_{y}-i_{y}}^{H}$表示对于相对宽度$j_{x}-i_{x}$和相对高度$j_{y}-i_{y}$学习到的嵌入表示
此时单头的计算变为:
$$O_{h}=Softmax(\frac{QK^{T}+S_{H}^{rel}+S_{W}^{rel}}{\sqrt{d_{k}^{h}}})V$$
- $S_{H}^{rel},S_{W}^{rel}\in R^{HW\times HW}$,它们是沿高度和宽度维度上的相对位置对数矩阵
- $S_{H}^{rel}[i,j]=q_{i}^{T}r_{j_{y}-i_{y}}^{H},S_{W}^{rel}[i,j]=q_{i}^{T}r_{j_{x}-i_{x}}^{W}$
注意力增强卷积
本文的提出的注意力增强卷积有以下两个特点:
- 使用一种注意力机制,可以同时关注整体空间和特征子空间(每个head对应一个特征子空间)
- 引入额外的特征图而不是细化它们
对应公式:
$$AAConv(X)=Concat[Conv(X),MHA(X)]$$
注意力增强卷积结构
- 每次增强卷积后都会通过一个batch normalization layer来缩放卷积特征图和注意力特征图的贡献
- 每个增强卷积都会使用残差块结构
- 由于注意力的计算具有较大的内存占用,所以本文从具有最小空间维度的最后一层慢慢加入注意力增强的卷积,直到遇到内存限制
- 采用较小的批量大小和使用步长为2的3 x 3平均池化来执行下采样,而通过双线性插值进行上采样等操作来减少网络的内存占用
实验
这部分只列举各个实验结果
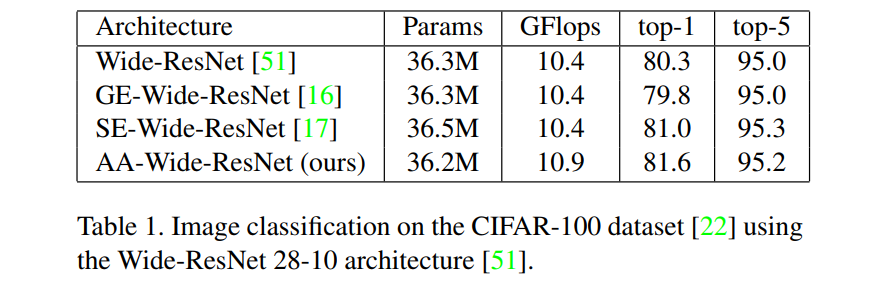
CIFAR-100
用于低分辨率图像的标准数据集
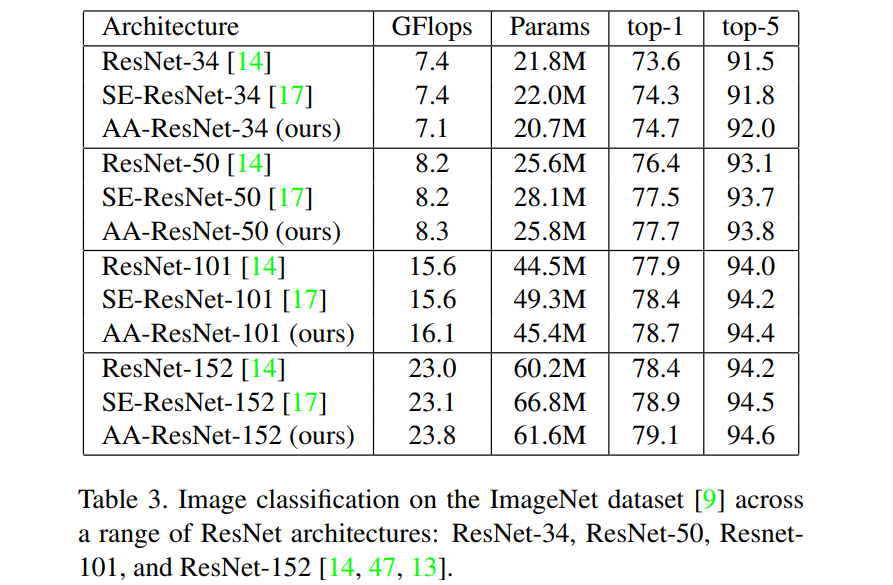
ImageNet
用于高分辨率图像的标准数据集,只列举其中一个
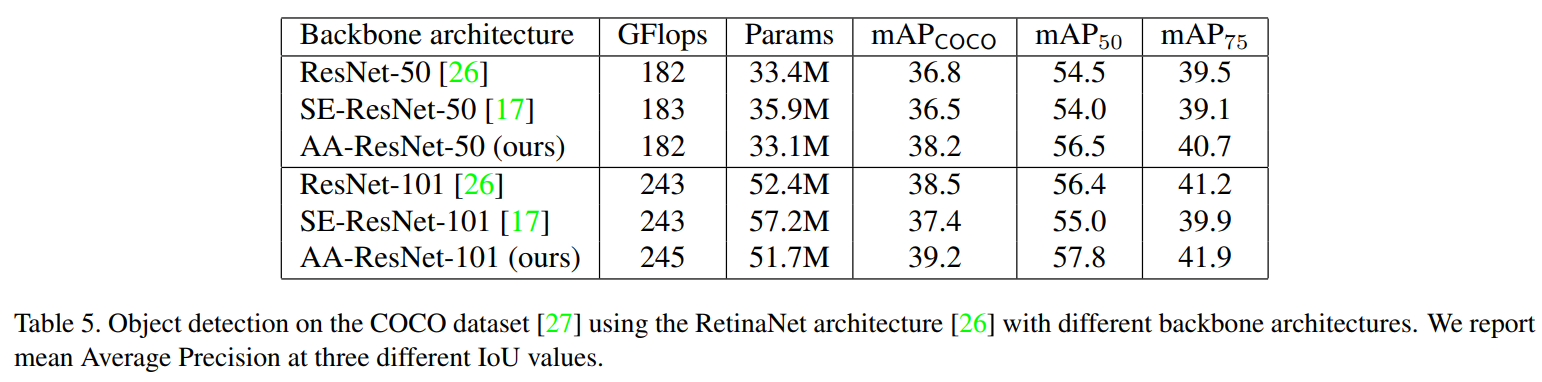
COCO dataset
用于目标检测的标准数据集
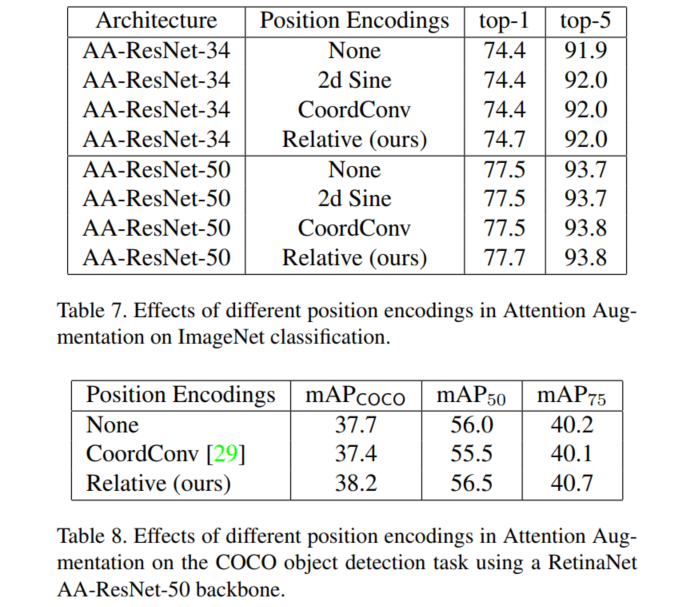
位置编码
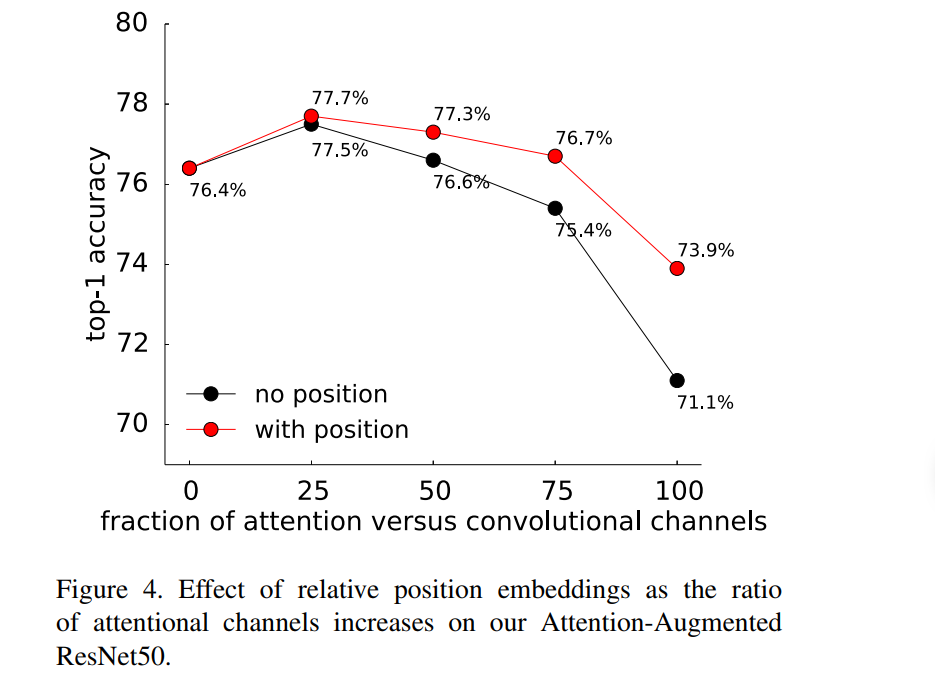
不同比例的注意力通道数