
前言
GAN以难训练而著称,在训练的过程中,模型没有收敛或者模型崩了是很常见的事。GAN通过生成器和判别器之间的对抗作用,使得生成器不断生成和原始数据概率分布相似的数据,从而达到以假乱真的目的。那怎样去学一个概率分布?从数学的角度就是学习一个概率密度函数,这个函数可以使得以下数学式在真实数据中最大(这和最大似然估计很相似)。下式中,$x^{(i)}$是真实的数据,P是概率密度函数
$$\underset{\theta \in R^{d}}{max}\frac{1}{m}\sum_{i=1}^{m}logP_{\theta}(x^{(i)})$$
如果我们知道真实数据的分布$P_{r}$和生成数据的分布$P_{g}$,那么我们只需最小化 KL 散度$KL(P_{r}||P_{g})$就可以使这两个分布相似,原始的GAN在KL散度这个评价标准做一定的推导进而得出训练原始GAN的损失函数 JS 散度,有关推导看这篇论文。但 JS 散度存在一个问题,真实数据$P_{r}$和生成数据$P_{g}$没有数据重叠的话,不管真实数据和生成数据之间的距离多远, JS 散度计算出来的值都是log2,这就造成了梯度消失的问题。以图像生成为例,图像是一个高维数据,真实数据的分布在这个高维空间中占据很小一部分,这就很难使两个分布有重叠部分,GAN也就很难训练。
因此,在这篇论文中,作者的着力点是怎样判断生成数据和真实数据两者的分布相似,换言之,怎样计算两个分布之间的距离,从而由这个距离得出新的损失函数来训练GAN。作者应用的是Wasserstein Distance,因此命名为Wasserstein GAN,即WGAN。初看 Wasserstein Distance 的公式,会觉得这根本就不是我能够学的。事实上,它们并不难,接下来我会用例子去解释它们。
EM距离
假设我们将分布P视为一堆土,而另一个分布Q视为它的目标。那么P和Q之间的EM距离(Earth Mover distance)是推土机将土堆P转换为土堆Q所消耗的最小成本。这样讲可能会很抽象,下面我将例举李宏毅老师课堂上的一个例子,来看EM距离是如何计算的。
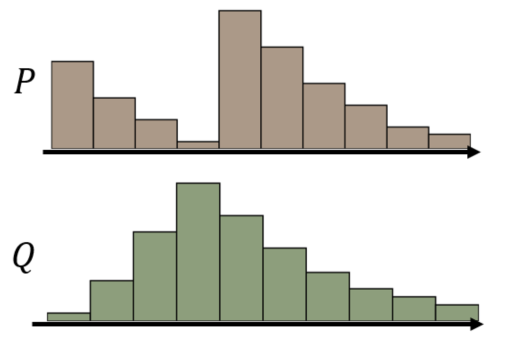
以上P和Q为两个分布,为了方便理解,我们可以将其看成两个土堆,同时你开着一个推土机。我想你有很多办法将P变成Q,那么你怎样操作会使消耗的功最小呢?
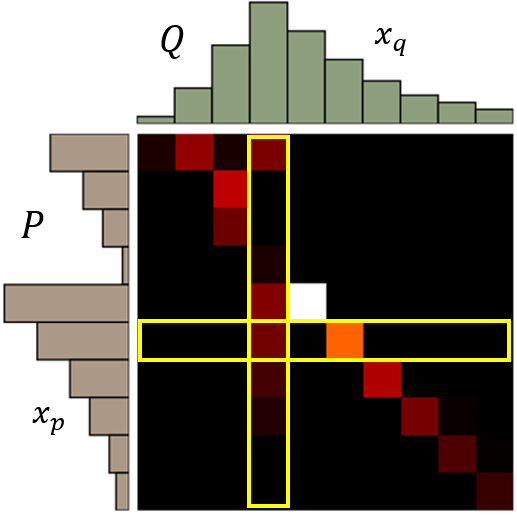
现在我们将其定义为一个数学问题,你“移动的计划”可以看成是一个矩阵,矩阵中每个位置的值可以看成你从土堆P的对应位置移动到土堆Q对应位置的土堆的重量。则移动计划$\gamma$的平均距离可以定义为
$$B(\gamma)=\underset{x_{p},x_{q}}{\sum}\gamma(x_{p},x_{q})||x_{p}-x_{q}||$$
式中,$x_{p},x_{q}$可以近似看成上图中矩阵对应的位置;$\gamma(\cdot)$表示移动的高度,也就是上面说的移动土的重量;$||\cdot||$表示两个位置对应坐标下的距离。
因此P和Q之间的EM距离可以看成求解下述问题得到最优解对应的,式中$\Pi$是所有可能的“移动计划”。
$$W(P,Q)=\underset{\gamma \in \Pi}{min}B(r)$$
以上述P和Q为例,它们的最佳“移动计划”如下图所示:

这篇论文第二章节用一个例子证明EM距离如何使得它收敛于一个简单的分布,而KL散度和JS散度是如何发散或者不收敛,具体可以查看原论文
WGAN
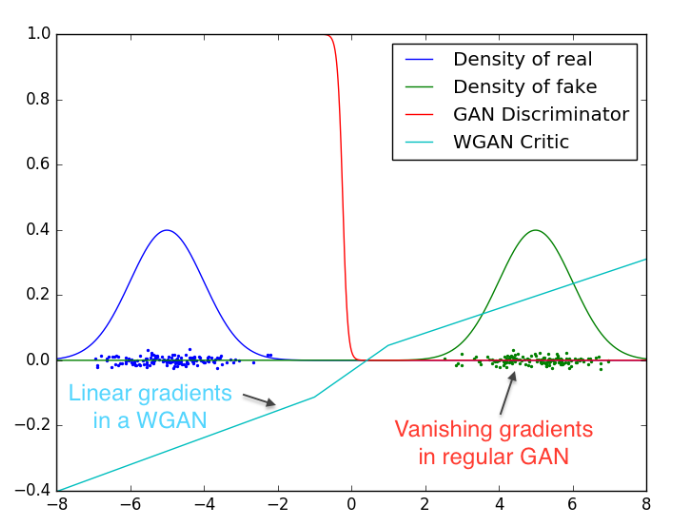
WGAN提出了一个新的成本函数,即使用Wasserstein距离,在任何地方都拥有一个更平滑的梯度。下图是GAN和WGAN的D(x)值的图,红线是GAN的,它充满了梯度消失或爆炸的区域。而相对于蓝线的WGAN,梯度在任何地方都比较平滑,即使生成器没有产生好的图像,也能够学习。
然而,Wasserstein距离的方程式是非常难解的。利用Kantorovich-Rubinstein duality,我们将其简化为
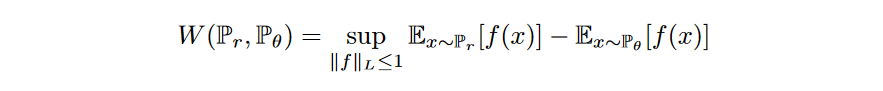
其中sup是最小的上界,f是一个遵循下面约束的1-Lipschitz函数
$$|f(x_1)-f(x_2)|\leq|x_1-x_2|$$
所以要想计算Wasserstein距离,我们还需找到一个1-Lipschitz函数。像其他深度学习问题,我们可以构建一个深度网络去学习这个函数,这个网络可以用判别器D实现,只不过最后一层不通过sigmoid函数,输出的是一些数值而不是一个概率值,这个数值可以理解为输出的图片有多真实。
WGAN和GAN在网络结构上设计几乎是一样的,不同点就是WGAN的判别器最后一层没有经过sigmoid函数。它们主要的区别主要是体现在损失函数上:

这里损失函数中f是一个1-Lipschitz函数,为例实现这一约束,WGAN使用了一个非常简单的技术——weight clipping,即将判别器的权重由超参数c控制,有了这些知识我们就能看懂论文中WGAN的算法:

实验
损失指标与图像质量之间的关系
在GAN中,损失衡量的是它对判别器的欺骗程度,而不是对图像质量的衡量。如下图所示,前面两个图使用正常GAN的训练算法,后面一张图使用WGAN训练算法。从中可以看出即使图像质量提高了,GAN中的生成器损失值也不会下降。因此,我们无法通过损失值来看出训练的进展(我们通常是展示训练过程生成的图像,然后通过我们的视觉来评价模型训练进程)。相反,WGAN损失函数的值可以反映了图像质量,随着损失值下降,生成图片的质量也上升了,这是我们所期待的。



提高训练的稳定性
WGAN做出的贡献有:
- 解决了模型崩溃的问题
- 不需要精心设计模型的网络结构
- 当判别器学习的很好,生成器仍然能够学习
下面我们展示论文中的实验结果,即使将DCGAN中的批量标准化去掉,WGAN仍然可以生成高质量的图片。



WGAN的问题
论文中作者是使用weight clipping技术来实现Lipschitz限制,但其实这是执行Lipschitz约束的一种糟糕的方式。作者文中也反映了这一问题,如果clipping参数的值很大,那么任何权重都需要很长时间才能达到限制,从而判别器很难训练到最优。如果clipping参数的值很小,当模型较深或未使用批量标准化,就很容易导致梯度消失的问题。
WGAN的困难在于执行Lipscitz约束条件,clipping虽然简单,但它解决了很多问题。虽然超参数c没有设置好,模型仍然会产生低质量的图片并且模型不能收敛。后面有文章用梯度惩罚执行Lipschitz约束条件,但它也有这样的问题,并且两者都会降低生成图片的多样性。真正完全满足Lipschitz约束条件的是Spectral Normalization,这两篇文章的链接:WGAN_GP、SNGAN,后续有时间的话,我也会学习这两篇文章,并和大家分享。



