前言
GAN是强大的生成模型,但是以难训练著称。前面一篇文章讲到的 WGAN 提升了 GAN 训练的稳定性,但有时候还是会产生不好的样本或收敛失败。在原始 WGAN 论文中,作者也提到了,这些问题主要是在判别器中使用 weight clipping 技术来实现 Lipschitz 限制导致的,特别是当超参数 c 没有设置合适。
$$w\leftarrow clip(w,-c,c)$$
WGAN 模型的性能对超参数 c 特别敏感。下图中,当判别器中没有使用批量标准化,c 从0.001增加到0.1,判别器从梯度消失转为梯度爆炸。

同时作者还证明了 weight clipping 降低了模型的表现能力并且限制了模型模拟复杂函数的能力。在下面的实验中,第一行是由 WGAN 估计的判别器值等高线图,第二行是由 WGAN 的一个变体估计的,即本文提出的方法WGAN_GP。从图中可以看出,WGAN 不能创造一个复杂的边界来包围模型的模式(橙色点),只是对最优函数进行了非常简单的近似模拟,而改进的 WGAN_GP 可以。

WGAN_GP
WGAN_GP使用梯度惩罚(gradient penalty)而不是 weight clipping 来实现 Lipschitz 限制:
$$|f(x_1)-f(x_2)|\leq K|x_1-x_2|$$
梯度惩罚
可微函数 1-Lipschtiz 在任何地方都有范数最多为1的梯度
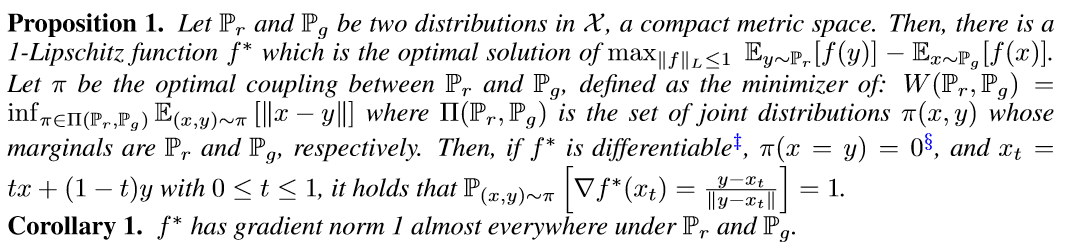
作者在论文中的附录 A 证明了命题1,感兴趣的可以看一下。论文连接:WGAN_GP
这个命题指出在真实数据和生成数据之间的插值点会有一个函数$f^{*}$的梯度规范为1。因此 WGAN_GP 使用的不是weight clipping,而是当其梯度规范偏离其目标规范值时对模型进行惩罚。WGAN_GP 的目标函数为:
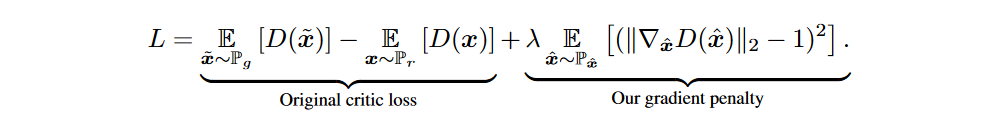
式中$\overset{\wedge}{x}=t\overset{\sim}{x}+(1-t)x,0\leq t\leq 1$,t是随机采样出来的;论文中,$\lambda$设置为10。
批量标准化禁止在判别器中使用,因为批量标准化会在相同批量的样本中建立联系,使得判别器从单一输入到单一输出的映射变成了从整批输入到整批输出的映射,而 WGAN_GP 惩罚的是判别器相对于每个输入的梯度规范,而不是整个批次,使用批量标准化会影响梯度惩罚的效率。
不可否认,引入梯度惩罚会增加计算成本,这可能并不是最优的选择,但作者通过实验证明 WGAN_GP 确实产生了一些更高质量的图像。
算法
有了前面的基础,限制让我们细看 WGAN_GP 算法的细节和梯度惩罚是怎样计算的。

与 WGAN 的算法进行对比,有两点不同:①使用了梯度惩罚,而不是 weight clipping;②使用了 Adam 优化算法,而不是 RMSProp 优化算法。
实验
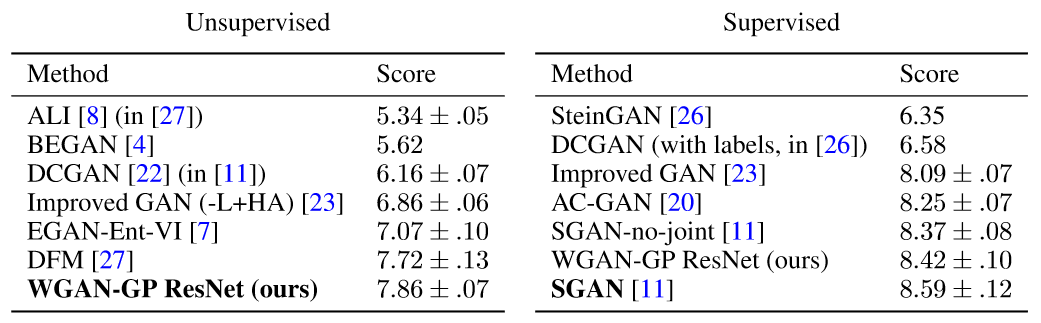
WGAN_GP 增强了训练的稳定性,如下图所示,当模型设计不是最优时,WGAN_GP 仍然可以生成高质量的图片,而反观其他模型,生成的可能就是一堆噪音。

下面是使用不同方法在 CIFAR-10 数据集上 Inception score 随生成器迭代次数的变化曲线。从图中可以看出,相对于 WGAN,WGAN_GP 收敛速度更快,且可以生成更高质量的图片,且使用 Adam 优化算法可以进一步提升模型的性能;相比于 DCGAN, WGAN_GP 收敛的慢些,但 Inception score 的收敛过程更加稳定。
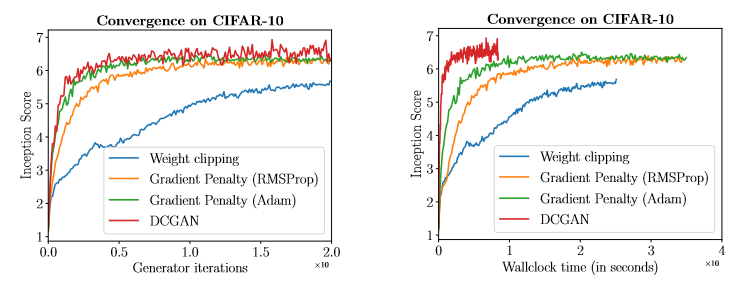
这是否就意味着 DCGAN 比 WGAN_GP 性能好?其实不然,WGAN_GP 的主要优势是它可以使训练更加稳定,使得模型更容易训练成功。为了验证 WGAN_GP 有助于模型收敛的更好,作者使用更加复杂的模型——深度残差网络作为生成器和判别器。下图就是不同模型在 LSUN 数据集上 Inception score 的结果,Inception score 越高,表示模型越好。