引言
前面我们学习过LSTM、GRU,它们都可以挖掘序列之间的某种联系。举个简单的例子——I saw a saw(我看见了一把锯子),句中两个saw无论在词义还是词性中都有所不同。如果将这句话简单做词向量处理,然后丢进一个全连接模型的话,那么两个saw输出的结果是一样的。因为对于这种模型而言的话,它是挖掘不出词与词之间的关系。而对于LSTM,GRU来说,它通过一定的机制可以学习到句子和句子之间的联系。
那么注意力机制是怎么学习这种联系的呢?这还得从我们人类的视觉说起。当我们在看到图片或风景的时候,我们会将注意力集中到我们关注的那些事物上。比如你在绘画的过程中,你会持续地关注你构思到画板上的元素(比如蓝天,白云),而不会太多关注那些其他的元素,比如风,虫鸣,阳光等等。这种有意识的聚焦就被称为注意力机制。那么机器是怎么将这种机制应用到模型中呢?这也是这篇文章要学习的内容。
注意力模型
仍然以I saw a saw为例,如下图所示,我们设置一个window,该window只考虑了周围三个输入,此时模型当前的输出就和周围三个输入有关。那么我们将window覆盖整个文本,是不是可以考虑整个句子中单词与单词之间的联系?
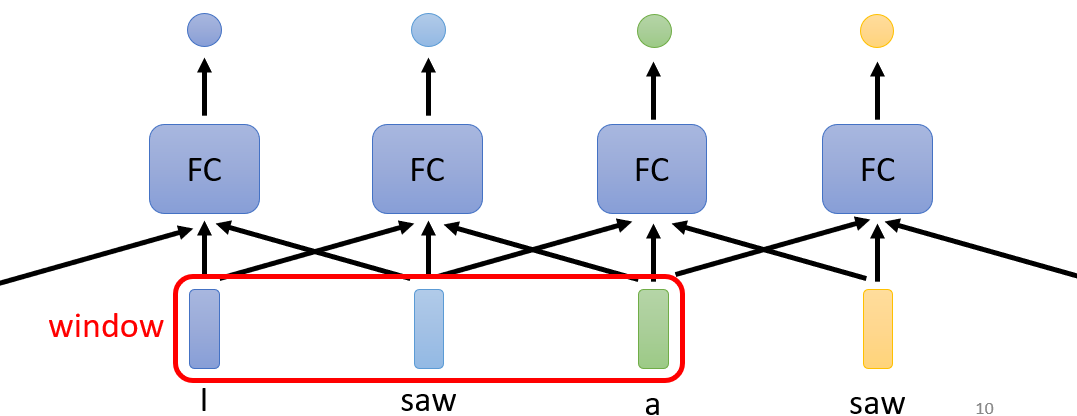
自注意力机制借鉴了这个想法,用一个结构实现上述Window中的操作,从而可以考虑句中每个单词之间的联系,进而区别出这两个saw。
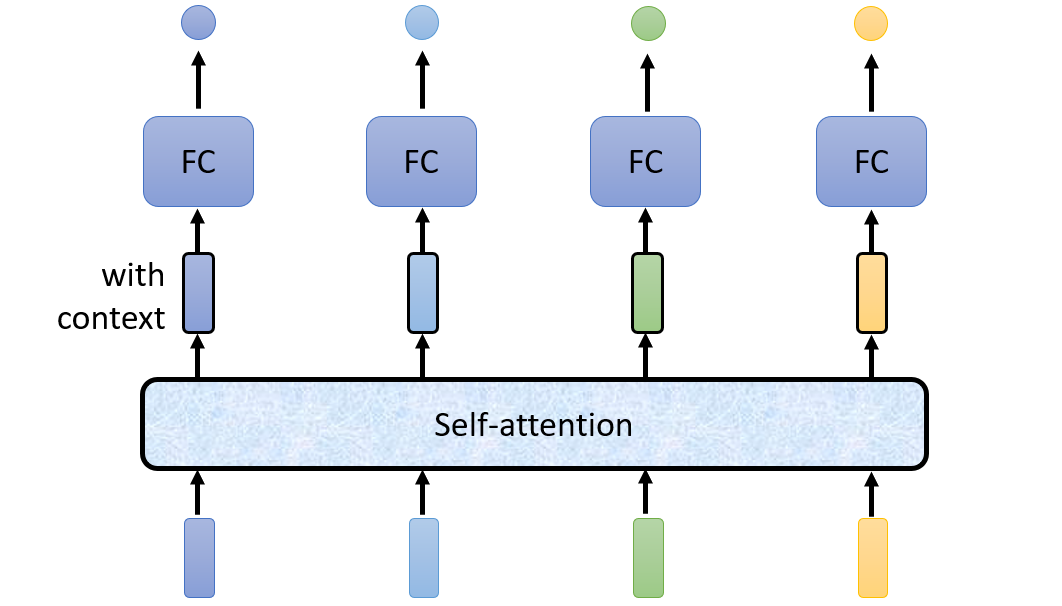
Attention机制通常有Bahdanau Attention(右图)与Luong Attention(左图),两种注意力的理论相似,Luong Attention的使用范围更广泛,因此本文主要讲解Luong Attention。在讲解Luong Attention前,我们先来讲解三个概念——查询、键和值。
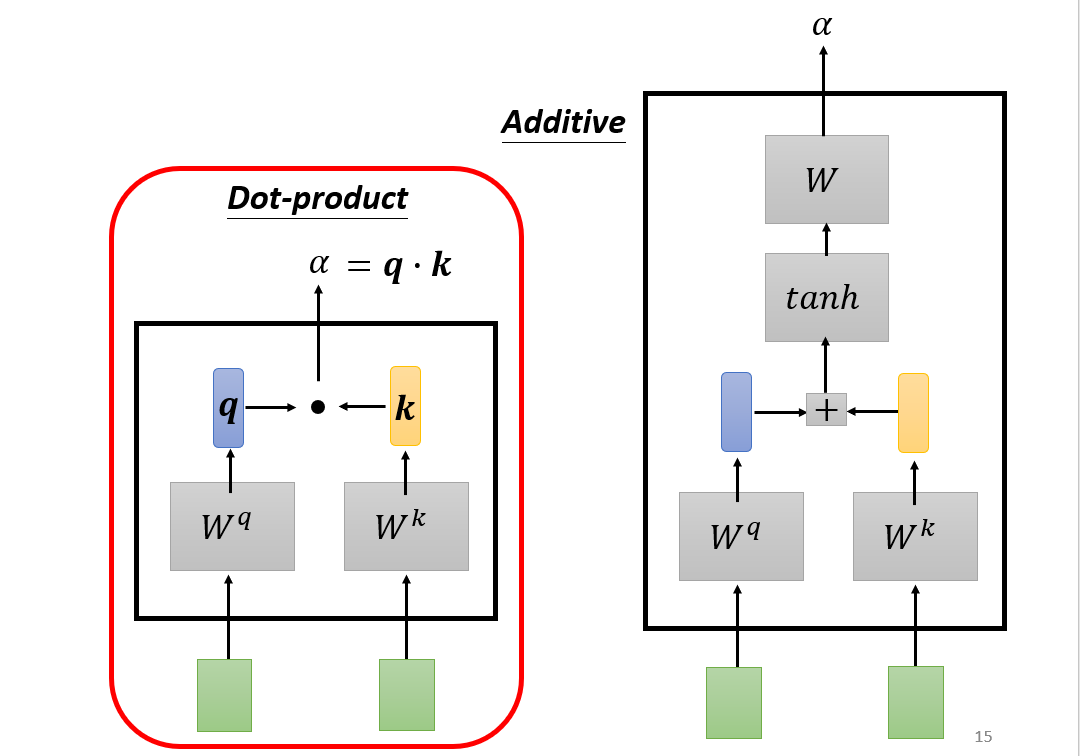
查询、键和值
在注意力机制的背景下,我们将自主性提示称为查询(query)。给定任何查询,注意力机制通过注意力汇聚将选择引导至感官输入。在注意力机制中,这些感官输入被称为值(value)。对于每个值都有一个键(key)与之配对,这可以想象成感官输入的非自主提示。通过注意力汇聚,每个查询(自主性提示)都可以与键(非自主性提示)进行匹配,这将引导得出最匹配的值(感官输入)。下面我们来看看查询、键和值是怎样在self-attention中运作的。
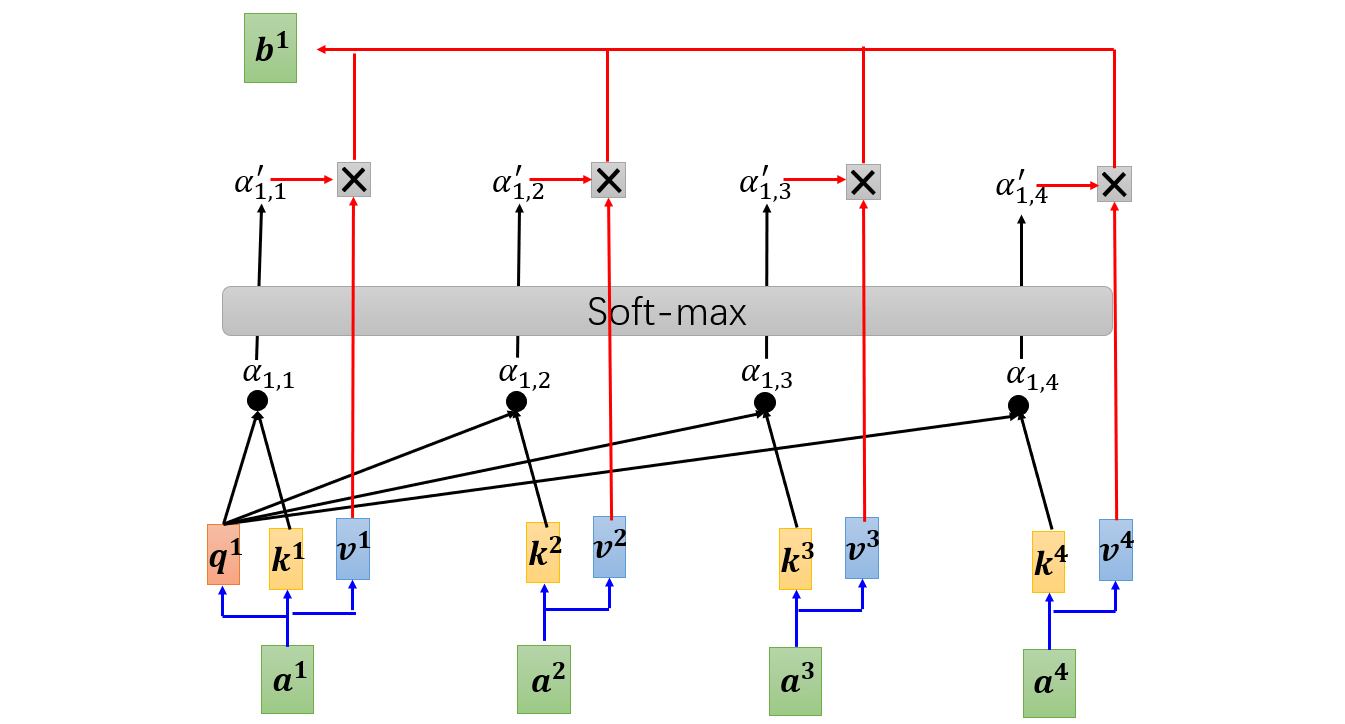
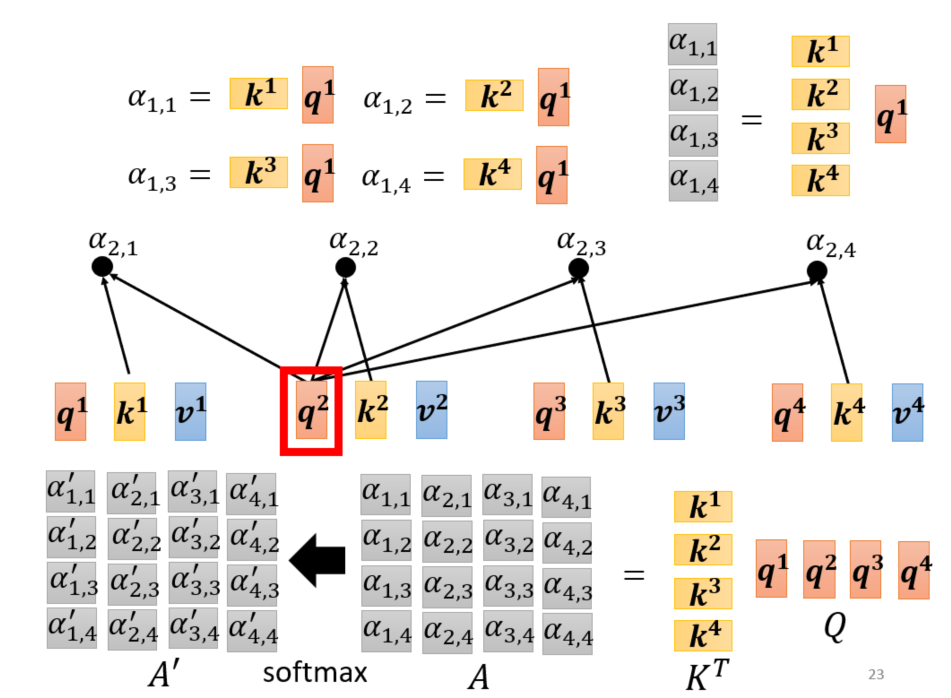
假设输入是:${a^{1},a^{2},a^{3},a^{4}}$。每个输入都对应查询、键和值。查询$q^{i}=W^{q}a^{i}$,键$k^{i}=W^{k}a^{i}$以及值$v^{i}=W^{v}a^{i}$。对于查询query,我们需要找所对应的键与之进行匹配,这样就可以得出那些信息比较重要。对应计算$a_{1,i}=q^{1}k^{i}$,再经过softmax层就可以算出每个信息对应的比重:
$$a_{1,i}^{‘}=exp(a_{1,i}/ \sum_{j}{a_{1,j}})$$
进而可以求出$a^{1}$对应的输出$b^{1}=\sum_{i}a^{‘}_{1,i}v^{i}$,同理我们可以计算出$b^{2},b^{3},b^{4}$。如果计算机也这样一个接一个计算,那计算效率太低。其实我们可以通过矩阵运算实现平行运算,具体操作如下:
查询:$$q^{i}=W^{q}a^{i}\Rightarrow (q^{1},q^{2},q^{3},q^{4})=W^{q}(a^{1},a^{2},a^{3},a^{4})$$
键:$$k^{i}=W^{k}a^{i}\Rightarrow (k^{1},k^{2},k^{3},k^{4})=W^{k}(a^{1},a^{2},a^{3},a^{4})$$
值:$$v^{i}=W^{v}a^{i}\Rightarrow (v^{1},v^{2},v^{3},v^{4})=W^{v}(a^{1},a^{2},a^{3},a^{4})$$
对于中间部分的计算可以用下图表示:
从而可以得到输出:
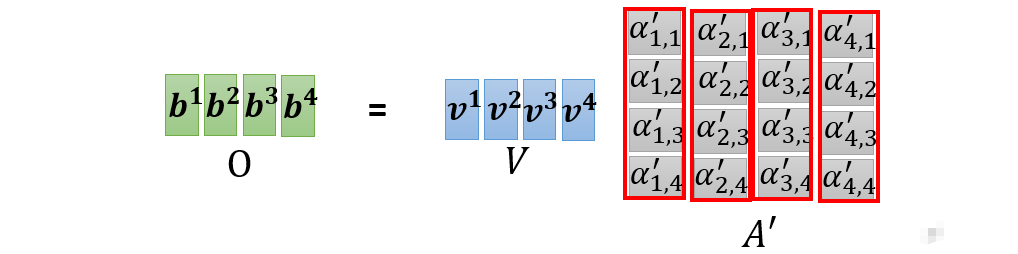
整理一下可得:
查询、键和值:$$Q,K,v=W^{q}I,W^{k}I,W^{v}I$$
注意力矩阵:$$A^{‘}\Leftarrow A=K^{T}Q$$
输出:$$O=VA^{‘}$$
由此可以看出 self-attention 需要率定的参数有$W^{q},W^{k},W^{v}$
多头自注意力模型
多头注意力(Multi-head Self-attention)模型是建立在自注意力模型的基础上。它模拟的是序列中存在不止一种的联系,这时单靠一个head是无法捕捉序列中的完整信息。以2 head为例,利用两组$W^{q},W^{k},W^{v}$对应输入$a^{i}$分别单独计算出两个输出$b^{i,1},b^{i,2}$,然后通过一个输出矩阵可以得出$b^{i}$:
$$b^{i}=W^{o}(b^{i,1},b^{i,2})^{T}$$
由此可以看出2 head带来了两倍以上的参数,虽然模型的准确度得到了提升,但是以损失计算能力为代价。
位置编码
self-attention虽然考虑了输入序列中每个成分之间的联系,但并没考虑输入序列的先后顺序。这是因为self-attention中的计算是平行计算,无论序列中两个成分相隔多远,对self-attention的整个计算没有什么影响。而对于某些实际应用,序列的顺序对模型影响很大或者可以一定程度上提升模型性能。举个例子,在词性标注中,我们知道动词是很少出现在一个句子的开头。所以当一个单词出现在句子的开头时,我们有很大的把握判断这个单词不是动词。
为了改进self-attention这个弱点,我们可以对输入进行一定的操作——位置编码,从而使得self-attention考虑到序列的顺序。这个操作其实很简单,我们只需在每个输入对应的位置加一个独一无二的位置向量即可实现:

这时你就会有一个疑问,位置编码是怎么确定的?具体可以看这篇论文:Learning to Encode Position for Transformer with Continuous Dynamical Model
Self-attention vs RNN
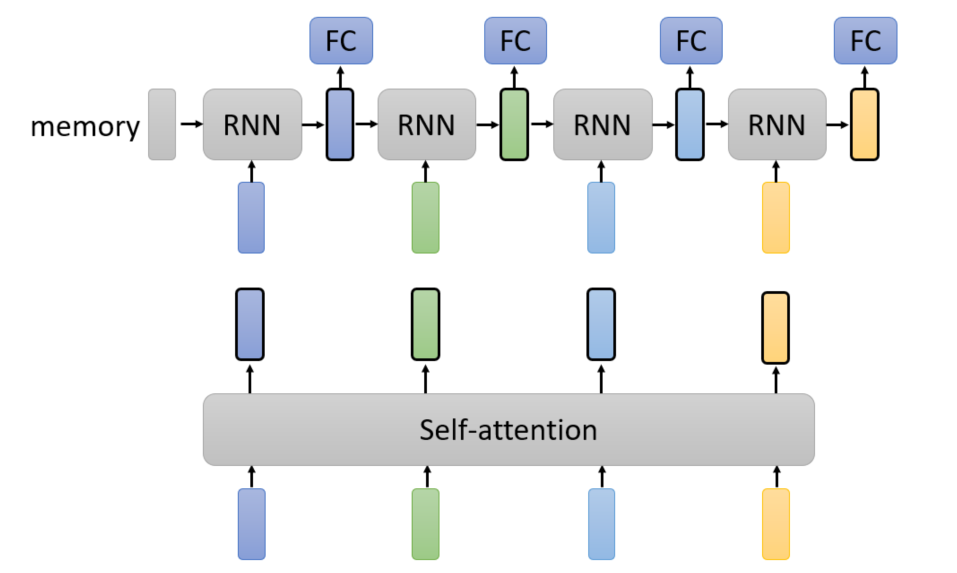
上图展示的是循环神经网络和自注意力模型的简易结构,由此可以看出self-attention相对RNN的结构优点:
- self-attention是平行计算,单次迭代计算速度块
- self-attention可以方便地考虑两个相隔较远的单词之间的联系,而RNN虽然也能考虑到,但RNN在传递的过程中,这种联系会消失。因此self-attention在处理序列中含有较大关联的模型中更有优势。
参考资料
[1] 李宏毅 机器学习2021



