基于GAN的多水库径流序列的随机生成

该文将DCGAN和WGAN结合起来组成一个新的方法DC-WGAN,并用于径流序列的随机生成。该方法可以同时捕捉径流序列在时间和空间维度上的相关性,解决了传统方法(如Copula等)在径流序列随机生成中时空相关性表现不足的问题。
引言
隐式随机优化(implicit stochastic optimization, ISO)模型是一种已广泛应用于水库系统中长期优化运行的方法。在实际工程中,水库历史序列的长度只有几十年,难以反映未来径流变化的随机性。因此径流序列的生成是弥补历史径流样本代表性和可靠性差的关键技术,是保证ISO模型准确性的前提。
对于单个水库,现有径流序列的样本时间长度能满足ISO的操作要求。但对于具有时空相关性的径流序列,当前样本的代表性和可靠性不足以满足。而具有时空相关性的径流序列的产生给水库系统联合优化运行的精细化管理带来了巨大的挑战。然而现有径流序列生成方法并没有体现水库间的时空相关性,它们有以下缺点:
- 难以扩展到高维,不适合多时间尺度的多水库系统的径流随机生成
- 径流序列的概率分布应事先假定,这在实际中不适用
- 难于捕捉高维数据的非线性特点,无法满足水库系统径流生成的要求
为解决上述问题,作者提出了一种基于GAN的径流序列的随机生成。GAN的特征有:①可以直接学习历史数据的分布,无需预先进行数据概率分布的假定;②无监督学习的模式避免繁琐的人工标注,适用于学习和生成大规模的数据集。作者将GAN的这些特点应用于径流系统的随机生成,创新点有:
- 从模型学习能力和泛化能力两个方面探索DC-WGAN在水库系统径流随机生成领域的随机性
- 与Copula方法相比,分析DC-WGAN径流样本的时空相关性
方法
GAN
生成式对抗网络(Generative adversarial network , GAN)在2014年被Goodfellow提出,已广泛用于计算机视觉和自然语言处理等领域。GAN通过生成器(generator)和判别器(discriminator)的对立实现了很好的生成效果。这两个网络的不同点在于,生成器的输入是一组随机噪音,作用是生成和目标数据分布相似的数据。而判别器的输入有真实数据和生成器生成的数据,输出是一个概率值,表示输入数据是历史数据的置信度。比如输出为1代表输入数据为真实数据,输出为0代表是生成数据。
假设我们有M个水库,每个水库拥有N年的历史径流数据,每年的径流数据被划分为T个时期。历史径流数据可以表示为
$${x^{t}_{i,j}},i=1,2,…,M;j=1,2,…,N;t=1,2,…,T$$
真实数据用$P_{data}(x)$表示,GAN的两个网络结构:生成器$G(z;\theta^{G})$,判别器$D(x;\theta^{D})$,其中$\theta^{G}$和$\theta^{D}$是这两个网络结构的权重参数(需要通过训练得到),z是一个已知分布的随机噪音。生成器的目标是产生的数据的分布要尽可能和真实数据的分布相似,用于“欺骗”判别器。而判别器的目标是区分数据是来源于真实数据还是生成数据。这两个网络在迭代过程中相互竞争以提高模型性能,最终生成的数据与真实数据基本一致。
在确定网络训练的目标后,我们需要分别为生成器和判别器制定损失函数(loss function)来训练这个模型。生成器的目标是“欺骗”判别器,因此生成器的目标是最大化$D(G(z))$。判别器的目标是区分数据,因此我们最小化$D(G(z))$并最大化$D(x),x\in P_{data}(x)$。因此损失函数$L_{G}和L_{D}$可以表示为:
$$L_{G}=E_{z\in p_{z}(z)}[log(1-D(G(z)))]$$
$$L_{D}=-E_{z\in p_{z}(z)}[log(1-D(G(z)))]-E_{x\in p_{data}(x)}[log(D(x))]$$
结合以上两个式子,则整个模型变成一个minimax游戏,其目标函数变为:
$$\underset{\theta_{G}}{min}\underset{\theta_{D}}{max}V(G,D)=E_{z\in p_{z}(z)}[log(1-D(G(z)))]+E_{x\in p_{data}(x)}[log(D(x))]$$
改进的GAN
原始生成式对抗网络存在的缺点
- 很难同时使两个网络同时收敛到最优,这就会影响模型训练的稳定性。举个简单例子,假设判别器的损失函数很短时间就收敛到0,那么生成器的参数就很难更新,这就导致生成器梯度消失的问题。
- 通过一定的数学假设,可以用JS散度来表示上面的目标函数,而JS散度存在一个问题,就是真实数据$P_{data}$和生成数据$P_{G}$没有数据重叠的话,不断真实数据和生成数据之间的距离多远,JS散度计算出来的值都是log2,这就导致了生成器梯度消失的问题。
大部分改进的GAN都是为了解决上述两个问题,其中DCGAN和WGAN是最有效且使用较为广泛的。
DCGAN
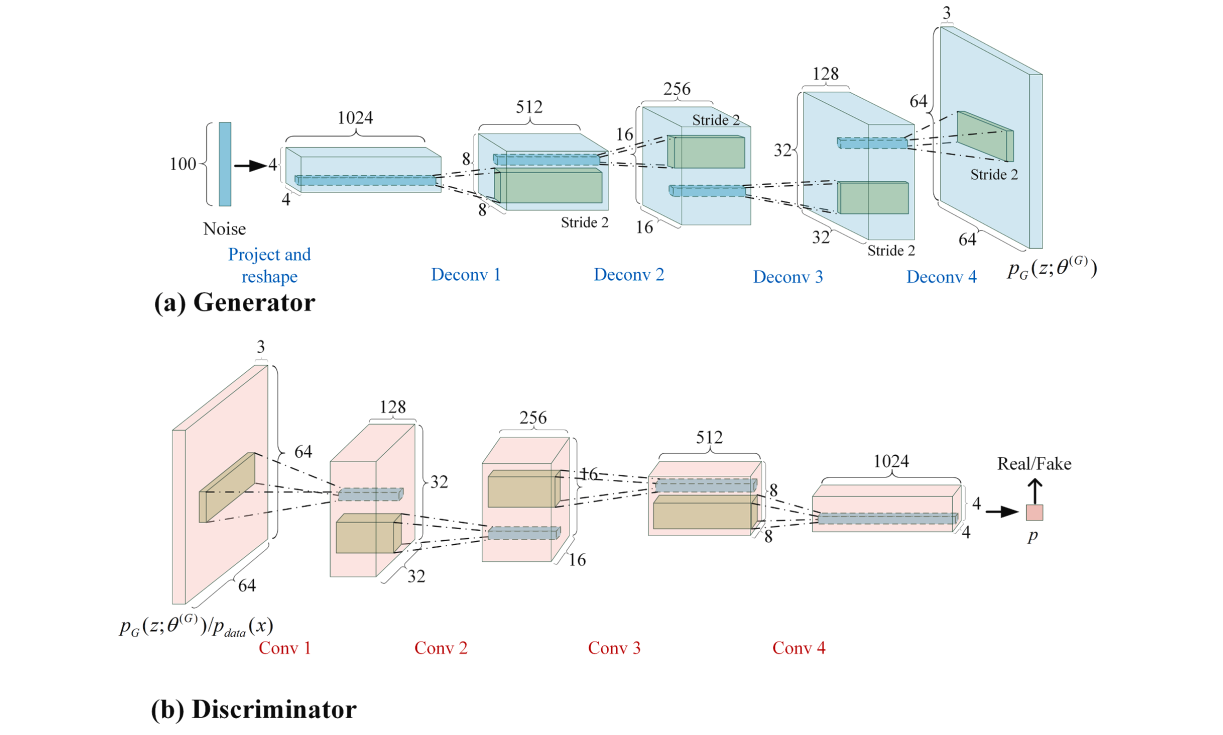
深度卷积生成式网络(deep convolutional generative adversarial network, DCGAN)在原始GAN模型的基础上,将生成器和判别器的网络结构换成了当时已经十分成熟的卷积神经网络结构,并对卷积神经网络结构进行一定的调整,克服了原始GAN训练不稳定和梯度消失的问题。具体改变有:
- 取消所有的pooling层。生成器中使用fractionally strided convolution代替pooling层,判别器中使用strided convolution代替pooling层。
- 在生成器和判别器中都使用批量标准化
- 去除了全连接层
- 生成器中使用ReLU作为激活函数,最后一层使用tanh激活函数
- 判别器中使用LeakyReLU作为激活函数
DCGAN的网络结构如下:
WGAN
Wasserstein生成式对抗网络使用Wasserstein Distance来替换掉JS-Divergence,解决了当生成数据和真实数据没有重叠时,JS散度为log2,从而导致生成器梯度消失的问题。WGAN的优点有:
- 判别器训练的越好,生成器就越好,这大大提高了原始GAN的稳定性
- 避免了模型在训练过程中崩溃,一定程度上提升了模型的鲁棒性
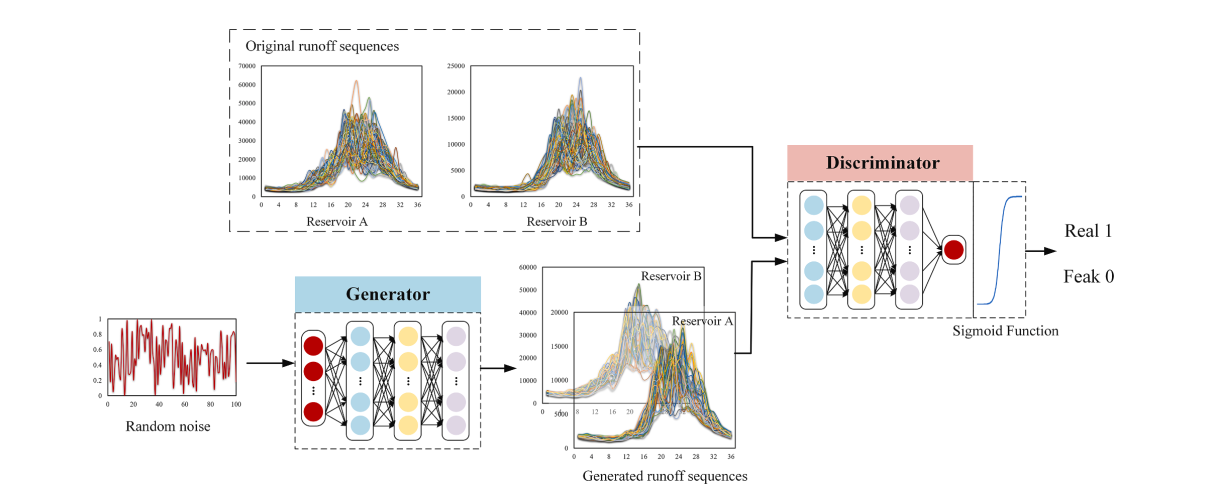
DC-WGAN
结合DCGAN和WGAN,作者提出了DC-WGAN模型,它的结构图如下:
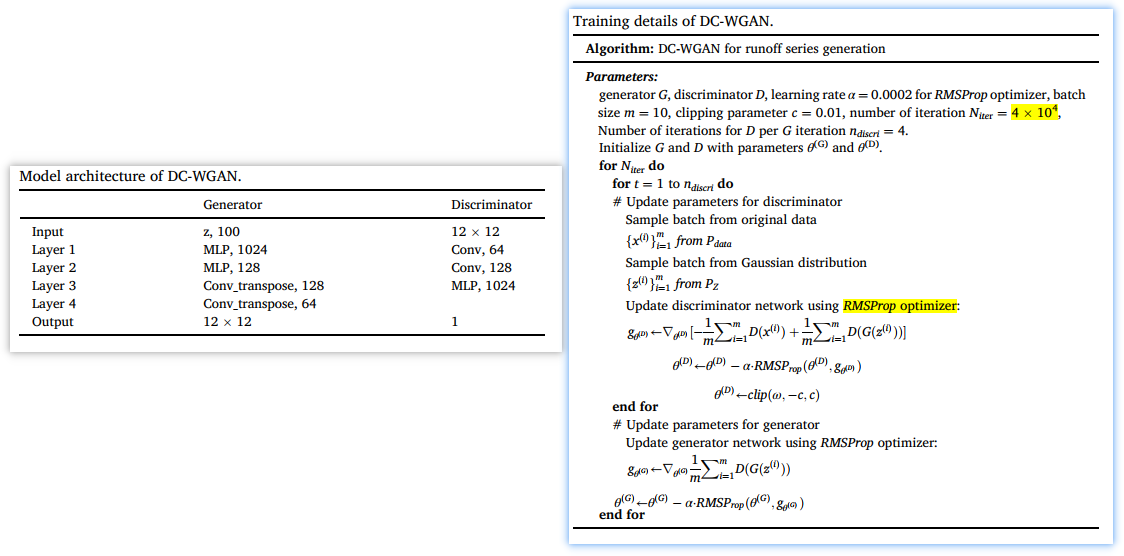
DC-WGAN的模型架构和算法流程分别看左图和右图:
研究区域
作者以中国下游金沙江梯级水库和三峡梯级水库为研究案例,包括溪洛渡、向家坝、三峡和葛洲坝四个水库。它们的地理位置如下图所示:
DC-WGAN模型的实验数据为这四个水库从1940到2010的径流序列,其中90%的径流序列(64年)被用于模型训练,10%(10年)被用于模型的验证。径流序列的时间尺度为10天,模型经过训练后产生3000个10天径流序列。
同时,用相同的数据,作者还用copula方法产生对应的径流序列,并将结果与DC_WGAN进行比较。
实验结果
学习能力
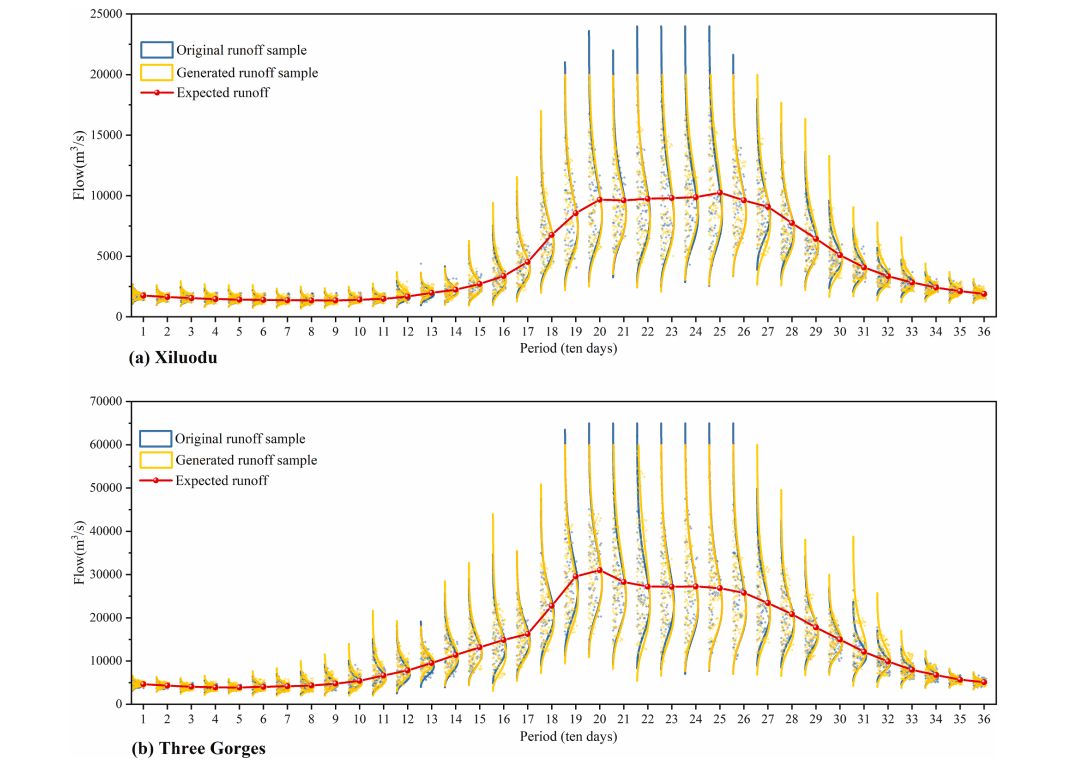
为了验证DC-WGAN的学习能力,原始径流序列和DC-WGAN生成的径流序列的频率曲线如下图所示。图中DC-WGAN生成的径流样本是随机从3000个生成样本随机选择了64个(和原始数据数量一样),频率曲线使用对数正态分布函数绘制。从图中可以看出两个频率曲线几乎完全重叠,说明DC-WGAN生成了正确分布的径流序列。
泛化能力
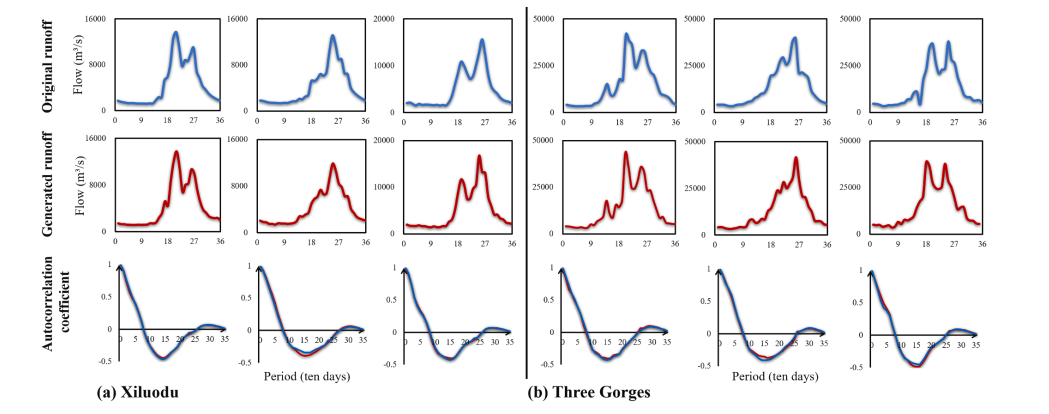
为了进一步验证DC-WGAN的泛化能力,作者使用欧几里得距离(Euclidean distance)在DC-WGAN生成的3000条径流数据中找出和7个验证数据最相似的。其中三个径流序列如下图所示。由图可以看出DC-WGAN可以生成与验证集相似形态的样本,说明模型具有很强的泛化能力,图中的自相关系数曲线也验证了DC-WGAN可以捕捉径流序列的时间相关性。
时间相关性
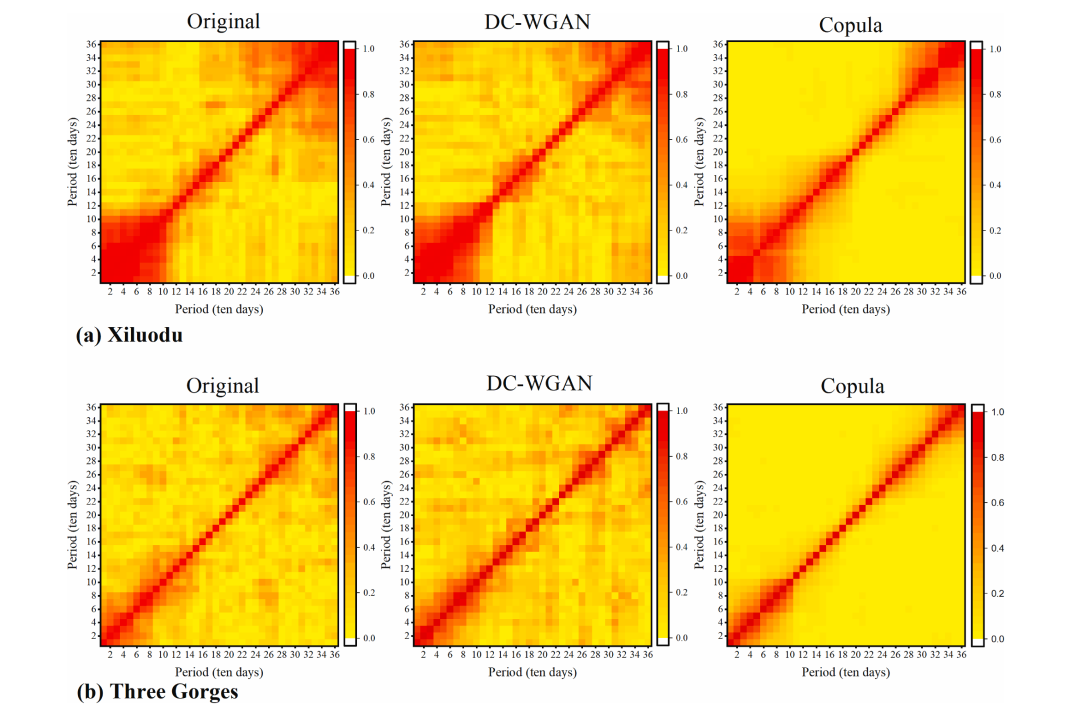
为了验证径流序列的时间相关性,作者分别绘制了原始样本和分别从DC-WGAN和Copula生成样本的相关系数热力图。从下图可以看出Copula生成序列的相关性弱于原始序列和DC-WGAN生成的序列,且基于Copula的生成方法无法捕捉到弱相关性,表明DC-WGAN可以更好地学习序列的时间相关性。
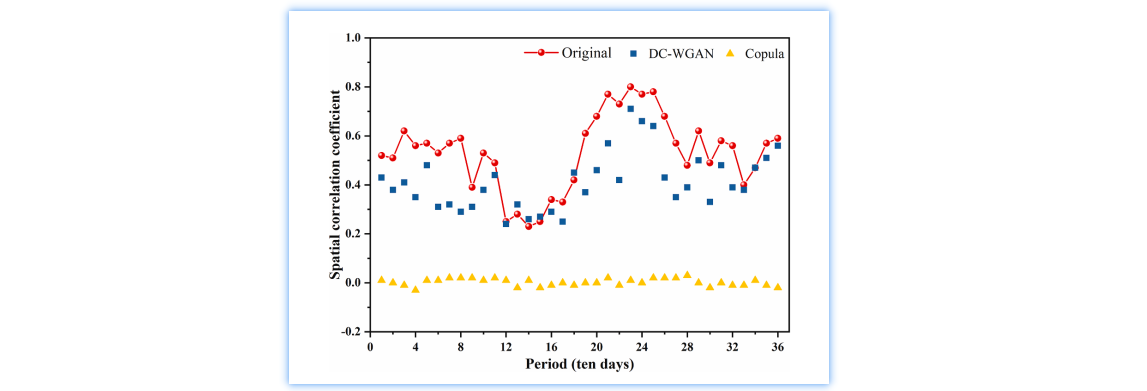
空间相关性
为了验证径流序列的空间相关性,基于原始样本、DC-WGAN和Copula生成样本,计算溪洛渡和三峡水库10天径流的空间相关系数,如下图所示。基于三种样本的平均年径流相关系数分别为0.67、0.65和-0.01。同时可以明显地看出,溪洛渡径流系列与三峡水库径流序列呈现出较强的空间相关性。DC-WGAN可以学习到水库间径流序列的空间相关性,但基于Copula的生成方法无法捕捉到不同水库间径流序列的空间相关性。