在这章节,我们将用RNN搭建一个seq2seq模型(sequences to sequences),实现英文到中文的翻译,数据集应用的是由Tatoeba项⽬的双语句⼦对114组成的“英-中文”数据集。
数据预处理
原始语料需要进行预处理,所以导入必要的包和模块。注意初次安装nltk后,进行分词需要依赖punkt,因此需要对其进行下载
import os
import jieba
import re
import random
from opencc import OpenCC
import nltk
from nltk.tokenize import word_tokenize
nltk.download('punkt')[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\kaxim\AppData\Roaming\nltk_data...
[nltk_data] Package punkt is already up-to-date!
True
词元化
该部分的作用是将数据词元化,用en,cn两个列表分别用来保存源语言(英语)和目标语言(中文)。在这两个列表中,对应列表索引的内容分别表示英语和其对应的中文翻译。
cc = OpenCC('t2s') # t2s -繁体转简体; s2t -简体转繁体
en, cn = [], []
data_dir = './data/cmn-eng/cmn.txt'
with open(data_dir, 'r', encoding='utf-8') as f:
for line in f.readlines():
sentence = re.split('\t', line) # sentence[0]为英文句子,sentence[1]为中文句子
sentence = list(filter(None, sentence))
en_sentence = ''
for word in word_tokenize(sentence[0]):
en_sentence += word.lower() + ' '
en.append(en_sentence)
cn_sentence = ''
for word in list(jieba.cut(sentence[1])):
word = re.sub(r'[ \n\t\r]', '', word)
if word == '':
continue
cn_sentence += cc.convert(word) + ' '
cn.append(cn_sentence)Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\kaxim\AppData\Local\Temp\jieba.cache
Loading model cost 0.429 seconds.
Prefix dict has been built successfully.
查看词元化后的结果
en[8000], cn[8000]('thanks for the memories . ', '感谢 那些 回忆 。 ')
构建字典
由于机器翻译数据集由语言对组成,因此我们需分别为源语言和目标语言构建字典,这样就方便之后转为one-hot vector。在该字典中,我们将出现次数少于3的低频率词视为相同未知词元(“<unk>”)。除此之外,我们还指定了额外的特定词元,例如在小批量时⽤于将序列填充到相同⻓度的填充词元(“<pad>”),以及序列的开始词元(“<bos>”)和结束词元(“<eos>”)。这些特殊词元在⾃然语⾔处理任务中⽐较常⽤。
构建的字典有以下两种形式:
int2word: 将整数转为对应文字
word2int: 将文字转为对应整数,该字典和前一个字典是一一对应关系
# 英文
words = {}
for sentence in en:
_sentence = re.split('[ \n\t\r ]', sentence)
_sentence = list(filter(None, _sentence))
for word in _sentence:
words[word] = words.get(word, 0) + 1
words =sorted(words.items(), key=lambda d: d[1], reverse=True) #排序
words = [word for word, count in words if count >= 2]
words = ['<PAD>', '<BOS>', '<EOS>', '<UNK>'] + words
word2int_en, int2word_en = {}, {}
for index,word in enumerate(words):
word2int_en[word] = index
int2word_en[index] = word
# 中文
words = {}
for sentence in cn:
_sentence = re.split('[ \n\t\r ]', sentence)
_sentence = list(filter(None, _sentence))
for word in _sentence:
words[word] = words.get(word, 0) + 1
words =sorted(words.items(), key=lambda d: d[1], reverse=True) #排序
words = [word for word, count in words if count >= 2]
words = ['<PAD>', '<BOS>', '<EOS>', '<UNK>'] + words
word2int_cn, int2word_cn = {}, {}
for index, word in enumerate(words):
word2int_cn[word] = index
int2word_cn[index] = word部分字典展示,由于字典不支持切片功能,因此我们需构建一个函数,实现切片功能
def dict_slice(adict, index):
keys = adict.keys()
dict_slice = {}
for k in list(keys)[: index]:
dict_slice[k] = adict[k]
return dict_slice英文字典
dict_slice(word2int_en, 15), dict_slice(int2word_en, 15)({'<PAD>': 0,
'<BOS>': 1,
'<EOS>': 2,
'<UNK>': 3,
'.': 4,
'i': 5,
'the': 6,
'to': 7,
'you': 8,
'a': 9,
'?': 10,
'is': 11,
'tom': 12,
"n't": 13,
'he': 14},
{0: '<PAD>',
1: '<BOS>',
2: '<EOS>',
3: '<UNK>',
4: '.',
5: 'i',
6: 'the',
7: 'to',
8: 'you',
9: 'a',
10: '?',
11: 'is',
12: 'tom',
13: "n't",
14: 'he'})
中文字典
dict_slice(word2int_cn, 15), dict_slice(int2word_cn, 15)({'<PAD>': 0,
'<BOS>': 1,
'<EOS>': 2,
'<UNK>': 3,
'。': 4,
'我': 5,
'的': 6,
'了': 7,
'你': 8,
'他': 9,
'?': 10,
'在': 11,
'汤姆': 12,
'是': 13,
'吗': 14},
{0: '<PAD>',
1: '<BOS>',
2: '<EOS>',
3: '<UNK>',
4: '。',
5: '我',
6: '的',
7: '了',
8: '你',
9: '他',
10: '?',
11: '在',
12: '汤姆',
13: '是',
14: '吗'})
构建训练资料
将数据划分成训练集,验证集和测试集
- 训练集:25000句
- 验证集:1000句
- 测试集:1965句
sentences = []
for en_sentence, cn_sentence in zip(en, cn):
# 去除中英文种出现3个未知词汇以上的句子
tokens = re.split('[ \n\t\r ]', en_sentence)
tokens = list(filter(None, tokens))
count = 0
for token in tokens:
index = word2int_en.get(token, 3)
if index == 3:
count += 1
if count >= 2:
continue
tokens = re.split('[ \n\t\r ]', cn_sentence)
tokens = list(filter(None, tokens))
count = 0
for token in tokens:
Index = word2int_cn.get(token, 3)
if Index == 3:
count += 1
if count >= 3:
continue
sentences.append(en_sentence + '\t' + cn_sentence)
sentences = list(set(sentences)) # 去重
random.seed(2022)
random.shuffle(sentences)
train_set = sentences[:25000]
validation_set = sentences[25000:26000]
test_set = sentences[26000:]
print(len(test_set))1965
定义dataset
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
# 首先定义一个函数,它可以将句子扩展到相同长度,以便模型训练
class LabelTransform(object):
def __init__(self, size, pad):
self.size = size
self.pad = pad
def __call__(self, label):
label = np.pad(label, (0, (self.size - label.shape[0])), mode='constant', constant_values=self.pad)
return label
# dataset
class EN2CNDataset(Dataset):
def __init__(self, max_output_len, set_name):
self.word2int_en, self.int2word_en = word2int_en, int2word_en
self.word2int_cn, self.int2word_cn = word2int_cn, int2word_cn
self.data = set_name
self.cn_vocab_size = len(self.word2int_cn)
self.en_vocab_size = len(self.word2int_en)
self.transform = LabelTransform(max_output_len, self.word2int_en['<PAD>'])
def __len__(self):
return len(self.data)
def __getitem__(self, index):
# 先将中英文分开
sentences = self.data[index]
sentences = re.split('[\t\n]', sentences)
sentences = list(filter(None, sentences))
# print(sentences)
assert len(sentences) == 2
# 预备特殊字符
BOS = self.word2int_en['<BOS>']
EOS = self.word2int_en['<EOS>']
UNK = self.word2int_en['<UNK>']
# 在开头添加 <BOS>,在结尾添加 <EOS> ,不在字典里面的 subword (词)用 <UNK> 代替
en, cn = [BOS], [BOS]
# 将句子拆解为 subword ,并用字典对应的整数取代
sentence = re.split(' ', sentences[0])
sentence = list(filter(None, sentence))
# print(f'en: {sentence}')
for word in sentence:
en.append(self.word2int_en.get(word, UNK))
en.append(EOS)
# 中文
sentence = re.split(' ', sentences[1])
sentence = list(filter(None, sentence))
# print(f'cn: {sentence}')
for word in sentence:
cn.append(self.word2int_cn.get(word, UNK))
cn.append(EOS)
en, cn = np.asarray(en), np.asarray(cn)
# print(en, cn)
# 用 <PAD> 将句子补到相同的长度
en, cn = self.transform(en), self.transform(cn)
# print(en, cn)
en, cn = torch.LongTensor(en), torch.LongTensor(cn)
return en, cnEncoder-Decoder模型
Encoder
seq2seq模型的编码器为RNN。对于每个输入,Encoder会输出一个向量和一个隐状态(hidden state),并将隐状态作为Decoder的输入。换句话说,Encoder会逐步读取输入序列,并输出单个向量(最终隐状态)
参数:
- en_vocab_size是英文字典的大小,也就是英文的subword的个数
- emb_dim是embedding的维度,主要将one-hot vector的单词向量压缩到指定的维度,主要是为了将维和浓缩资讯的功能,可以使用预先训练好的word embedding
- hid_dim是RNN输出和隐状态的维度
- n_layers是RNN要叠多少层
- dropout是决定有多少的概率会将某个节点变为0,主要是为了防止过拟合,一般来说是在训练时使用,测试时则不适用
Encoder的输入:
- 英文的整数序列
输出:
- outputs:最上层RNN全部的输出,可以用Attention进行处理
- hidden:每层最后的隐状态,将传递到Decoder进行解码
import torch
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, en_vocab_size, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.embedding = nn.Embedding(en_vocab_size, emb_dim)
self.hid_dim = hid_dim
self.n_layers = n_layers
self.rnn = nn.GRU(emb_dim, hid_dim, n_layers, dropout=dropout, batch_first=True, bidirectional=True)
self.dropout = nn.Dropout(dropout)
def forward(self, input):
# input = [batch size, sequence len, vocab size]
embedding = self.embedding(input)
outputs, hidden = self.rnn(self.dropout(embedding))
# outputs = [batch size, sequence len, hid dim * directions]
# hidden = [num_layers * directions, batch size , hid dim]
# outputs 是最上层RNN的输出
return outputs, hiddenDecoder
Decoder是另一个RNN,在最简单的seq2seq decoder中, 仅使用Encoder每一层最后的隐状态来进行解码,这个隐状态用作Decoder的初始隐状态,本节先做最简单的Decoder,你也可以尝试将Encoder的输出用于Attention机制加到Decoder的输入中。
参数:
- cn_vocab_size是中文字典的大小,也就是中文的subword的个数
- emb_dim是embedding的维度,主要将one-hot vector的单词向量压缩到指定的维度,主要是为了将维和浓缩资讯的功能,可以使用预先训练好的word embedding
- hid_dim是RNN输出和隐状态的维度
- n_layers是RNN要叠多少层
- dropout是决定有多少的概率会将某个节点变为0,主要是为了防止过拟合,一般来说是在训练时使用,测试时则不适用
Decoder的输入:
- 前一次解码出来的单词的整数表示
输出:
- hidden:根据输入和前一次的隐状态,现在的隐状态更新的结果
- output:每个字有多少概率是这次解码的结果
class Decoder(nn.Module):
def __init__(self, cn_vocab_size, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.cn_vocab_size = cn_vocab_size
self.hid_dim = hid_dim * 2 # Encoder使用双向RNN的缘故
self.n_layers = n_layers
self.embedding = nn.Embedding(cn_vocab_size, emb_dim)
self.input_dim = emb_dim
self.rnn = nn.GRU(self.input_dim, self.hid_dim, self.n_layers, dropout=dropout, batch_first=True)
self.embedding2vocab = nn.Sequential(
nn.Linear(self.hid_dim, self.hid_dim * 4),
nn.Linear(self.hid_dim * 4, self.cn_vocab_size),
)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden):
# input = [batch size, vocab size]
# hidden = [batch size, n layers * directions, hid dim]
# Decoder 只会是单向的,所以 directions=1
input = input.unsqueeze(1) # input(batch_size, 1, vocab_size)
embedded = self.dropout(self.embedding(input)) # embedded(batch_size, 1, embed_dim)
output, hidden = self.rnn(embedded, hidden)
# output(batch_size, 1, hid_dim * 2) hidden(batch_size, num_layers * 1, hid_dim * 2)
# 将 RNN 的输出转为每个词出现的概率
prediction = self.embedding2vocab(output.squeeze(1))
# prediction(batch_size, cn_vocab_size)
return prediction, hiddenSeq2Seq
这部分是整个seq2seq模型的构建,实现Encoder和Decoder的联合。简单来说就是Encoder接受输入得到输出,将Encoder的输出传给Decoder,然后将Decoder得到的输出传回Decoder进行解码,解码完成后,将Decoder的输出传回,就这样一直到输出中解码出<EOS>
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, input, target, teacher_forcing_ratio):
# input = [batch size, input len, vocab size]
# target = [batch size, target len, vocab size]
# teacher_forcing_ratio 是有多少概率使用正确答案来计算
batch_size = target.shape[0]
target_len = target.shape[1]
vocab_size = self.decoder.cn_vocab_size
# 准备一个储存空间来储存输出
outputs = torch.zeros(batch_size, target_len, vocab_size).cuda()
# 输入进入Encoder
encoder_outputs, hidden = self.encoder(input)
# Encoder 最后的隐状态(hidden state)用来初始化 Decoder
# encoder_outputs 主要是使用在 Attention
# 因为 Encoder 是双向的RNN,所以需要将同一层两个方向的 hidden state 连接在一起
# hidden = [num_layers * directions, batch size , hid dim] --> [num_layers, directions, batch size , hid dim]
hidden = hidden.view(self.encoder.n_layers, 2, batch_size, -1)
hidden = torch.cat((hidden[:, -2, :, :], hidden[:, -1, :, :]), dim=2)
# 取的 <BOS> token
input = target[:, 0]
preds = []
for t in range(1, target_len):
output, hidden = self.decoder(input, hidden)
outputs[:, t] = output
# 决定是否用正确答案来做训练
teacher_force = random.random() <= teacher_forcing_ratio
# 取出概率最大的单词
top1 = output.argmax(1)
# 如果是 teacher force 则用正解训练,反之用自己预测的单词训练
input = target[:, t] if teacher_force and t < target_len else top1
preds.append(top1.unsqueeze(1))
preds = torch.cat(preds, 1)
return outputs, preds
def inference(self, input, target):
# input = [batch size, input len, vocab size]
# target = [batch size, target len, vocab size]
batch_size = target.shape[0]
target_len = target.shape[1]
vocab_size = self.decoder.cn_vocab_size
# 准备一个储存空间来储存输出
outputs = torch.zeros(batch_size, target_len, vocab_size).cuda()
# 输入进入Encoder
encoder_outputs, hidden = self.encoder(input)
# Encoder 最后的隐状态(hidden state)用来初始化 Decoder
# encoder_outputs 主要是使用在 Attention
# 因为 Encoder 是双向的RNN,所以需要将同一层两个方向的 hidden state 连接在一起
# hidden = [num_layers * directions, batch size , hid dim] --> [num_layers, directions, batch size , hid dim]
hidden = hidden.view(self.encoder.n_layers, 2, batch_size, -1)
hidden = torch.cat((hidden[:, -2, :, :], hidden[:, -1, :, :]), dim=2)
# 取的 <BOS> token
input = target[:, 0]
preds = []
for t in range(1, target_len):
output, hidden = self.decoder(input, hidden)
outputs[:, t] = output
# 取出概率最大的单词
top1 = output.argmax(1)
input = top1
preds.append(top1.unsqueeze(1))
preds = torch.cat(preds, 1)
return outputs, predsUtils
储存模型
def save_model(model, optimizer, store_model_path, step):
torch.save(model.state_dict(), f'{store_model_path}/model_{step}.ckpt')载入模型
def load_model(model, load_model_path):
print(f'Load model from {load_model_path}')
model.load_state_dict(torch.load(f'{load_model_path}.ckpt'))
return model构建模型
def build_model(config, en_vocab_size, cn_vocab_size):
# 构建模型
encoder = Encoder(en_vocab_size, config.emb_dim, config.hid_dim, config.n_layers, config.dropout)
decoder = Decoder(cn_vocab_size, config.emb_dim, config.hid_dim, config.n_layers, config.dropout)
model = Seq2Seq(encoder, decoder)
print(model)
model = model.cuda()
# optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
print(optimizer)
if config.load_model:
model = load_model(model, config.load_model_path)
model = model.cuda()
return model, optimizer数字转句子
def tokens2sentence(outputs, int2word):
sentences = []
for tokens in outputs:
sentence = []
for token in tokens:
word = int2word[int(token)]
if word == '<EOS>':
break
sentence.append(word)
sentences.append(sentence)
return sentences计算BLEU score
import nltk
from nltk.translate.bleu_score import sentence_bleu
from nltk.translate.bleu_score import SmoothingFunction
def computebleu(sentences, targets):
score = 0
assert (len(sentences) == len(targets))
def cut_token(sentence):
tmp = []
for token in sentence:
if token == '<UNK>' or token.isdigit() or len(bytes(token[0], encoding='utf-8')) == 1:
tmp.append(token)
else:
tmp += [word for word in token]
return tmp
for sentence, target in zip(sentences, targets):
sentence = cut_token(sentence)
target = cut_token(target)
score += sentence_bleu([target], sentence, weights=(1, 0, 0, 0))
return score迭代dataloader
def infinite_iter(data_loader):
it = iter(data_loader)
while True:
try:
ret = next(it)
yield ret
except StopIteration:
it = iter(data_loader)训练与测试
实际工作中,训练一个好的机器翻译模型需要大量的语料,训练的周期长。本次实验数据集简单,训练耗时短,定义的训练和测试函数如下:
def train(model, optimizer, train_iter, loss_function, total_steps, summary_steps, train_dataset, teacher_forcing_ratio):
model.train()
model.zero_grad()
losses = []
loss_sum = 0.0
for step in range(summary_steps):
sources, targets = next(train_iter)
sources, targets = sources.cuda(), targets.cuda()
outputs, preds = model(sources, targets, teacher_forcing_ratio)
# targets 的第一个 token 是 <BOS> 所以忽略
outputs = outputs[:, 1:].reshape(-1, outputs.size(2))
targets = targets[:, 1:].reshape(-1)
loss = loss_function(outputs, targets)
optimizer.zero_grad()
loss.backward()
grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), 1)
optimizer.step()
loss_sum += loss.item()
if (step + 1) % 5 == 0:
loss_sum = loss_sum / 5
print ("\r", "train [{}] loss: {:.3f}, Perplexity: {:.3f} ".format(total_steps + step + 1, loss_sum, np.exp(loss_sum)), end=" ")
losses.append(loss_sum)
loss_sum = 0.0
return model, optimizer, losses
def test(model, dataloader, loss_function):
model.eval()
loss_sum, bleu_score= 0.0, 0.0
n = 0
result = []
for sources, targets in dataloader:
sources, targets = sources.cuda(), targets.cuda()
batch_size = sources.size(0)
outputs, preds = model.inference(sources, targets)
# targets 的第一個 token 是 <BOS> 所以忽略
outputs = outputs[:, 1:].reshape(-1, outputs.size(2))
targets = targets[:, 1:].reshape(-1)
loss = loss_function(outputs, targets)
loss_sum += loss.item()
# 將預測結果轉為文字
targets = targets.view(sources.size(0), -1)
preds = tokens2sentence(preds, dataloader.dataset.int2word_cn)
sources = tokens2sentence(sources, dataloader.dataset.int2word_en)
targets = tokens2sentence(targets, dataloader.dataset.int2word_cn)
for source, pred, target in zip(sources, preds, targets):
result.append((source, pred, target))
# 計算 Bleu Score
bleu_score += computebleu(preds, targets)
n += batch_size
return loss_sum / len(dataloader), bleu_score / n, result训练流程
先训练后测试
def train_process(config):
# 准备训练资料
train_dataset = EN2CNDataset(config.max_output_len, train_set)
train_loader = DataLoader(train_dataset, batch_size=config.batch_size, shuffle=True)
train_iter = infinite_iter(train_loader)
# 准备验证资料
val_dataset = EN2CNDataset(config.max_output_len, validation_set)
val_loader = DataLoader(val_dataset, batch_size=1)
# 构建模型
model, optimizer = build_model(config, train_dataset.en_vocab_size, train_dataset.cn_vocab_size)
loss_function = nn.CrossEntropyLoss(ignore_index=0)
train_losses, val_losses, bleu_scores = [], [], []
total_steps = 0
while (total_steps < config.num_steps):
# 训练模型
model, optimizer, loss = train(model, optimizer, train_iter, loss_function, total_steps, config.summary_steps, train_dataset, config.teacher_forcing_ratio)
train_losses += loss
# 验证模型
val_loss, bleu_score, result = test(model, val_loader, loss_function)
val_losses.append(val_loss)
bleu_scores.append(bleu_score)
total_steps += config.summary_steps
print ("\r", "val [{}] loss: {:.3f}, Perplexity: {:.3f}, blue score: {:.3f} ".format(total_steps, val_loss, np.exp(val_loss), bleu_score))
# 储存模型的结果
if total_steps % config.store_steps == 0 or total_steps >= config.num_steps:
save_model(model, optimizer, config.store_model_path, total_steps)
with open(f'{config.store_model_path}/output_{total_steps}.txt', 'w') as f:
for line in result:
print (line, file=f)
return train_losses, val_losses, bleu_scores测试模型
def test_process(config):
# 准备测试资料
test_dataset = EN2CNDataset(config.max_output_len, test_set)
test_loader = DataLoader(test_dataset, batch_size=1)
# 构建模型
model, optimizer = build_model(config, test_dataset.en_vocab_size, test_dataset.cn_vocab_size)
print ("Finish build model")
loss_function = nn.CrossEntropyLoss(ignore_index=0)
model.eval()
# 测试模型
test_loss, bleu_score, result = test(model, test_loader, loss_function)
# 储存结果
with open(f'./log/cmn-eng/test_output.txt', 'w') as f:
for line in result:
print(line, file=f)
return test_loss, bleu_scoreConfig
- 实验的参数设定表
class configurations(object):
def __init__(self):
self.batch_size = 64
self.emb_dim = 256
self.hid_dim = 512
self.n_layers = 2
self.dropout = 0.5
self.learning_rate = 0.00005
self.teacher_forcing_ratio = 0.8
self.max_output_len = 40 # 最后输出句子的最大长度
self.num_steps = 12000 # 总训练次数
self.store_steps = 300 # 训练多少次后需存模型
self.summary_steps = 300 # 训练多少次后需检验是否有过拟合
self.load_model = False # 是否需载入模型
self.store_model_path = "./log/ckpt" # 储存模型的位置
self.load_model_path = "./log/ckpt/model_12000" # 载入模型的位置 e.g. "./ckpt/model_{step}"
self.data_path = "./data/cmn-eng" # 资料存放的位置
self.attention = False # 是否使用 Attention Mechanism训练模型:
config = configurations()
train_losses, val_losses, bleu_scores = train_process(config)Seq2Seq(
(encoder): Encoder(
(embedding): Embedding(4397, 256)
(rnn): GRU(256, 512, num_layers=2, batch_first=True, dropout=0.5, bidirectional=True)
(dropout): Dropout(p=0.5, inplace=False)
)
(decoder): Decoder(
(embedding): Embedding(6798, 256)
(rnn): GRU(256, 1024, num_layers=2, batch_first=True, dropout=0.5)
(embedding2vocab): Sequential(
(0): Linear(in_features=1024, out_features=4096, bias=True)
(1): Linear(in_features=4096, out_features=6798, bias=True)
)
(dropout): Dropout(p=0.5, inplace=False)
)
)
Adam (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
eps: 1e-08
lr: 5e-05
weight_decay: 0
)
train [300] loss: 0.911, Perplexity: 2.488
val [300] loss: 5.124, Perplexity: 168.024, blue score: 0.186
val [600] loss: 4.827, Perplexity: 124.873, blue score: 0.233
val [900] loss: 4.643, Perplexity: 103.901, blue score: 0.278
val [1200] loss: 4.538, Perplexity: 93.484, blue score: 0.291
val [1500] loss: 4.514, Perplexity: 91.273, blue score: 0.288
val [1800] loss: 4.457, Perplexity: 86.216, blue score: 0.307
val [2100] loss: 4.504, Perplexity: 90.364, blue score: 0.313
val [2400] loss: 4.392, Perplexity: 80.830, blue score: 0.333
val [2700] loss: 4.389, Perplexity: 80.539, blue score: 0.329
val [3000] loss: 4.380, Perplexity: 79.800, blue score: 0.342
val [3300] loss: 4.319, Perplexity: 75.126, blue score: 0.357
val [3600] loss: 4.245, Perplexity: 69.757, blue score: 0.358
val [3900] loss: 4.262, Perplexity: 70.927, blue score: 0.371
val [4200] loss: 4.241, Perplexity: 69.500, blue score: 0.375
val [4500] loss: 4.234, Perplexity: 68.983, blue score: 0.387
val [4800] loss: 4.186, Perplexity: 65.791, blue score: 0.385
val [5100] loss: 4.122, Perplexity: 61.675, blue score: 0.396
val [5400] loss: 4.162, Perplexity: 64.201, blue score: 0.399
val [5700] loss: 4.148, Perplexity: 63.323, blue score: 0.410
val [6000] loss: 4.065, Perplexity: 58.286, blue score: 0.404
val [6300] loss: 4.089, Perplexity: 59.695, blue score: 0.410
val [6600] loss: 4.076, Perplexity: 58.931, blue score: 0.417
val [6900] loss: 4.103, Perplexity: 60.544, blue score: 0.423
val [7200] loss: 4.102, Perplexity: 60.452, blue score: 0.426
val [7500] loss: 4.092, Perplexity: 59.838, blue score: 0.429
val [7800] loss: 4.029, Perplexity: 56.186, blue score: 0.433
val [8100] loss: 4.057, Perplexity: 57.809, blue score: 0.440
val [8400] loss: 4.023, Perplexity: 55.880, blue score: 0.440
val [8700] loss: 4.025, Perplexity: 55.962, blue score: 0.445
val [9000] loss: 4.043, Perplexity: 57.014, blue score: 0.450
val [9300] loss: 4.020, Perplexity: 55.690, blue score: 0.453
val [9600] loss: 4.030, Perplexity: 56.256, blue score: 0.460
val [9900] loss: 4.032, Perplexity: 56.365, blue score: 0.465
val [10200] loss: 4.056, Perplexity: 57.730, blue score: 0.454
val [10500] loss: 4.001, Perplexity: 54.639, blue score: 0.465
val [10800] loss: 4.055, Perplexity: 57.664, blue score: 0.461
val [11100] loss: 4.007, Perplexity: 55.003, blue score: 0.470
val [11400] loss: 4.063, Perplexity: 58.153, blue score: 0.468
val [11700] loss: 4.042, Perplexity: 56.917, blue score: 0.474
val [12000] loss: 4.072, Perplexity: 58.686, blue score: 0.475
测试模型:
在执行这步之前,请先去config设定所要载入模型的位置,并将load_model设置为True
config.load_model = True
test_loss, bleu_score = test_process(config)
print(f'test loss: {test_loss}, bleu_score: {bleu_score}')Seq2Seq(
(encoder): Encoder(
(embedding): Embedding(4397, 256)
(rnn): GRU(256, 512, num_layers=2, batch_first=True, dropout=0.5, bidirectional=True)
(dropout): Dropout(p=0.5, inplace=False)
)
(decoder): Decoder(
(embedding): Embedding(6798, 256)
(rnn): GRU(256, 1024, num_layers=2, batch_first=True, dropout=0.5)
(embedding2vocab): Sequential(
(0): Linear(in_features=1024, out_features=4096, bias=True)
(1): Linear(in_features=4096, out_features=6798, bias=True)
)
(dropout): Dropout(p=0.5, inplace=False)
)
)
Adam (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
eps: 1e-08
lr: 5e-05
weight_decay: 0
)
Load model from ./log/ckpt/model_12000
Finish build model
test loss: 4.043186987083377, bleu_score: 0.470621067287946
图形化训练过程
训练的loss变化趋势
import matplotlib.pyplot as plt
plt.figure()
plt.plot(train_losses)
plt.xlabel('次数')
plt.ylabel('loss')
plt.title('train loss')
plt.show()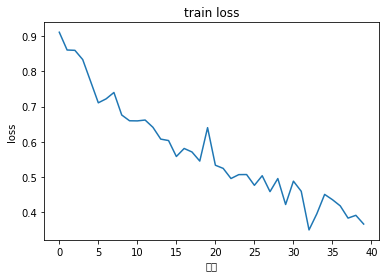
验证的loss变化趋势
import matplotlib.pyplot as plt
plt.figure()
plt.plot(val_losses)
plt.xlabel('次数')
plt.ylabel('loss')
plt.title('validation loss')
plt.show()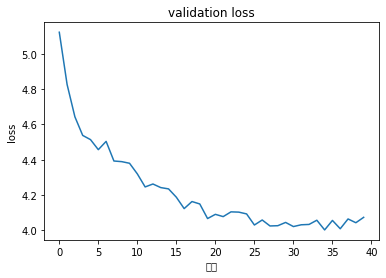
BLEU score
import matplotlib.pyplot as plt
plt.figure()
plt.plot(bleu_scores)
plt.xlabel('次数')
plt.ylabel('BLEU score')
plt.title('BLEU score')
plt.show()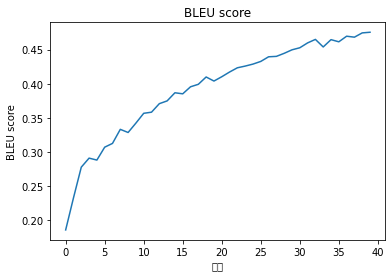
参考资料
[1] 李宏毅 机器学习2020



