作业描述
本作业处理的是一个phoneme分类,是一个多元分类问题。phoneme是语言的一种语音的一种语音单位,可以用来区分一个词和另一个词,如下面黑体部分。
- bat / pat , bad / bed
作业使用的数据集是TIMIT Acoustic-Phonetic Continuous Speech Corpus,采用的数据格式如下:
timit_11/
- train_11.npy –> 训练数据
- train_label_11.npy –> 逐帧phoneme标签(0-38)
- test_11.npy –> 测试数据
# 导入需要的包
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
import time
import random
import matplotlib.pyplot as plt
seed = 2022
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True定义一些函数
def get_device():
''' Get device (if GPU is available, use GPU) '''
return 'cuda' if torch.cuda.is_available() else 'cpu'
def plot_learning_curve(loss_record, title=''):
''' Plot learning curve of your model (train & dev loss) '''
total_steps = len(loss_record['train'])
x_1 = range(total_steps)
x_2 = x_1[::len(loss_record['train']) // len(loss_record['dev'])]
plt.figure(figsize=(6, 4))
plt.plot(x_1, loss_record['train'], c='tab:red', label='train')
plt.plot(x_2, loss_record['dev'], c='tab:cyan', label='dev')
plt.ylim(0.0, 5.)
plt.xlabel('Training steps')
plt.ylabel('MSE loss')
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
def plot_accuracy(acc_record, title=''):
''' Plot accuracy of your model (train & dev acc) '''
total_steps = len(acc_record['train'])
x = range(total_steps)
plt.figure(figsize=(6, 4))
plt.plot(x, acc_record['train'], c='tab:red', label='train')
plt.plot(x, acc_record['dev'], c='tab:cyan', label='dev')
plt.ylim(0.0, 1.)
plt.xlabel('Training epochs')
plt.ylabel('accuracy')
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()数据预处理
加载数据
从.npy文件中加载训练和测试数据
print("Loading data ...")
data_root = './timit_11/'
train = np.load(data_root + 'train_11.npy')
train_label = np.load(data_root + 'train_label_11.npy')
test = np.load(data_root + 'test_11.npy')
print('Size of training data: {}'.format(train.shape))
print('Size of testing data: {}'.format(test.shape))Loading data ...
Size of training data: (1229932, 429)
Size of testing data: (451552, 429)
Dataset
class TIMITDataset(Dataset):
def __init__(self, X, y=None):
self.data = torch.from_numpy(X).float()
if y is not None:
y = y.astype(np.int)
self.label = torch.LongTensor(y)
else:
self.label = None
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
if self.label is not None:
return self.data[idx], self.label[idx]
else:
return self.data[idx]将训练数据划分为训练集和验证集,你可以通过改变变量 VAL_RATIO 来修改验证集的比例
VAL_RATIO = 0.2
percent = int(train.shape[0] * (1 - VAL_RATIO))
train_x, val_x, train_y, val_y = train[: percent], train[percent:], train_label[: percent], train_label[percent:]
print('Size of training set: {}'.format(train_x.shape))
print('Size of validation set: {}'.format(val_x.shape))Size of training set: (983945, 429)
Size of validation set: (245987, 429)
DataLoader
根据Dataset制作DataLoader,你可以修改下面的变量 BATCH_SIZE
BATCH_SIZE= 64
train_set = TIMITDataset(train_x, train_y)
val_set = TIMITDataset(val_x, val_y)
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_set, batch_size=BATCH_SIZE, shuffle=False)模型实现相关函数
模型搭建
这部分可以自行修改,注意输入数据的维度为429,数据类别有39种
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
self.net = nn.Sequential(
nn.Linear(429, 1024), nn.BatchNorm1d(1024), nn.ReLU(), nn.Dropout(0.2),
nn.Linear(1024, 512), nn.BatchNorm1d(512), nn.ReLU(), nn.Dropout(0.2),
nn.Linear(512, 128), nn.BatchNorm1d(128), nn.ReLU(), nn.Dropout(0.2),
nn.Linear(128, 39),
)
def forward(self, x):
return self.net(x)训练
def train(train_loader, val_loader, model, config, device):
''' 训练模型 '''
n_epochs = config['n_epochs'] # 最大迭代次数
optimizer = torch.optim.Adam(model.parameters(), lr=config['lr']) # optimizer使用Adam
criterion = nn.CrossEntropyLoss() # 损失函数使用CrossEntropyLoss
best_acc = 0.0 # 用于记录验证时最好的准确率,并将此时的模型
loss_record = {'train': [], 'dev': []} # 记录训练损失
acc_record = {'train': [], 'dev': []} # 记录预测准确度
for epoch in range(n_epochs):
start_time = time.time()
train_acc, train_loss = 0.0, 0.0
model.train()
for i, data in enumerate(train_loader):
optimizer.zero_grad() # 将模型参数的 gradient 至0
pred = model(data[0].to(device)) # 前向传播
loss = criterion(pred, data[1].to(device)) # 计算loss
loss.backward() # 利用后向传播算出每个参数的gradient
optimizer.step() # 更新模型参数
train_acc += np.sum(np.argmax(pred.cpu().data.numpy(), axis=1) == data[1].numpy())
train_loss += loss.detach().cpu().item()
loss_record['train'].append(loss.detach().cpu().item())
train_acc /= len(train_loader.dataset)
train_loss /= len(train_loader)
acc_record['train'].append(train_acc)
# 每次迭代后,在验证集中验证你的模型
dev_acc, dev_loss = dev(val_loader, model, device, criterion)
acc_record['dev'].append(dev_acc)
loss_record['dev'].append(dev_loss)
# 将结果打印出来
print('[%02d/%02d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \
(epoch + 1, n_epochs, time.time() - start_time, train_acc, train_loss, dev_acc, dev_loss))
# 当模型性能提升时保存模型
if dev_acc > best_acc:
best_acc = dev_acc
print(f'Saving model (epoch = {epoch+1:02d}, accuracy = {best_acc:.4f})')
torch.save(model.state_dict(), config['save_path']) # 保存模型到指定路径
return best_acc, loss_record, acc_record验证
def dev(dv_set, model, device, criterion):
model.eval()
dev_loss, dev_acc = 0, 0
for i, data in enumerate(dv_set):
with torch.no_grad():
pred = model(data[0].to(device)) # 前向传播
loss = criterion(pred, data[1].to(device)) # 计算loss
dev_acc += np.sum(np.argmax(pred.cpu().data.numpy(), axis=1) == data[1].numpy())
dev_loss += loss.detach().cpu().item()
dev_acc /= len(dv_set.dataset)
dev_loss /= len(dv_set)
return dev_acc, dev_loss设置超参数
config中包含模型训练的超参数(可以进行调节)和保存模型的路径
device = get_device()
os.makedirs('models', exist_ok=True)
# 可以进行调节来提升模型性能
config = {
'n_epochs': 20, # 最大迭代次数
'lr': 0.0001,
'save_path': 'models/model.pth' # 模型保存路径
}模型加载和训练
model = Classifier().to(device)
best_acc, loss_record, acc_record = train(train_loader, val_loader, model, config, device)[01/20] 61.04 sec(s) Train Acc: 0.575976 Loss: 1.418989 | Val Acc: 0.679743 loss: 1.018808
Saving model (epoch = 01, accuracy = 0.6797)
[02/20] 59.27 sec(s) Train Acc: 0.636308 Loss: 1.162909 | Val Acc: 0.697712 loss: 0.942522
Saving model (epoch = 02, accuracy = 0.6977)
[03/20] 57.94 sec(s) Train Acc: 0.655783 Loss: 1.090724 | Val Acc: 0.708123 loss: 0.903914
Saving model (epoch = 03, accuracy = 0.7081)
[04/20] 57.50 sec(s) Train Acc: 0.667945 Loss: 1.045382 | Val Acc: 0.716786 loss: 0.870373
Saving model (epoch = 04, accuracy = 0.7168)
[05/20] 57.50 sec(s) Train Acc: 0.676864 Loss: 1.011510 | Val Acc: 0.720506 loss: 0.856811
Saving model (epoch = 05, accuracy = 0.7205)
[06/20] 57.69 sec(s) Train Acc: 0.684058 Loss: 0.983198 | Val Acc: 0.724416 loss: 0.837952
Saving model (epoch = 06, accuracy = 0.7244)
[07/20] 57.36 sec(s) Train Acc: 0.690473 Loss: 0.961224 | Val Acc: 0.726238 loss: 0.831526
Saving model (epoch = 07, accuracy = 0.7262)
[08/20] 56.88 sec(s) Train Acc: 0.695339 Loss: 0.943797 | Val Acc: 0.728803 loss: 0.821308
Saving model (epoch = 08, accuracy = 0.7288)
[09/20] 56.70 sec(s) Train Acc: 0.699613 Loss: 0.928245 | Val Acc: 0.729120 loss: 0.819629
Saving model (epoch = 09, accuracy = 0.7291)
[10/20] 57.16 sec(s) Train Acc: 0.703794 Loss: 0.913152 | Val Acc: 0.733738 loss: 0.803043
Saving model (epoch = 10, accuracy = 0.7337)
[11/20] 56.80 sec(s) Train Acc: 0.706580 Loss: 0.901354 | Val Acc: 0.735575 loss: 0.798162
Saving model (epoch = 11, accuracy = 0.7356)
[12/20] 56.79 sec(s) Train Acc: 0.709608 Loss: 0.888328 | Val Acc: 0.735815 loss: 0.793815
Saving model (epoch = 12, accuracy = 0.7358)
[13/20] 57.12 sec(s) Train Acc: 0.712408 Loss: 0.879705 | Val Acc: 0.736096 loss: 0.796301
Saving model (epoch = 13, accuracy = 0.7361)
[14/20] 57.16 sec(s) Train Acc: 0.715146 Loss: 0.869005 | Val Acc: 0.738202 loss: 0.787290
Saving model (epoch = 14, accuracy = 0.7382)
[15/20] 57.15 sec(s) Train Acc: 0.717777 Loss: 0.860623 | Val Acc: 0.737059 loss: 0.793017
[16/20] 57.05 sec(s) Train Acc: 0.719551 Loss: 0.853531 | Val Acc: 0.737689 loss: 0.788586
[17/20] 57.11 sec(s) Train Acc: 0.721698 Loss: 0.845117 | Val Acc: 0.739344 loss: 0.784496
Saving model (epoch = 17, accuracy = 0.7393)
[18/20] 57.78 sec(s) Train Acc: 0.723899 Loss: 0.838226 | Val Acc: 0.740059 loss: 0.784261
Saving model (epoch = 18, accuracy = 0.7401)
[19/20] 58.68 sec(s) Train Acc: 0.725527 Loss: 0.832501 | Val Acc: 0.739783 loss: 0.782018
[20/20] 58.36 sec(s) Train Acc: 0.726496 Loss: 0.827860 | Val Acc: 0.742173 loss: 0.777942
Saving model (epoch = 20, accuracy = 0.7422)
可视化显示
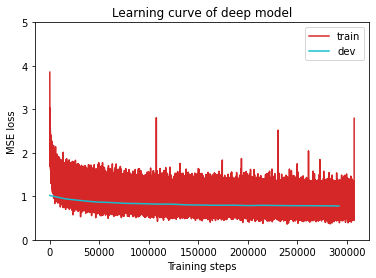
可视化显示可以看出训练过程中是否存在过拟合、模型不合适等问题
展示训练集和验证集中loss的变化
plot_learning_curve(loss_record, title='deep model')
展示训练集和验证集中acc随迭代次数的变化
plot_accuracy(acc_record, title='deep model')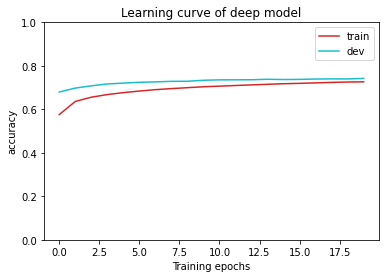
模型测试
创建测试dataloader,从模型保存路径中加载模型
# 创建dataloader
test_set = TIMITDataset(test, None)
test_loader = DataLoader(test_set, batch_size=BATCH_SIZE, shuffle=False)
# 加载模型
del model
model = Classifier().to(device)
model.load_state_dict(torch.load(config['save_path'])) 预测
model.eval()
preds = []
for x in test_loader:
x = x.to(device)
with torch.no_grad():
pred = model(x)
pred = np.argmax(pred.cpu().data.numpy(), axis=1)
for y in pred:
preds.append(y)将测试集上的预测结果保存到.csv文件中
with open("predict.csv", 'w') as f:
f.write('Id,Category\n')
for i, y in enumerate(preds):
f.write('{},{}\n'.format(i, y))


