作业描述
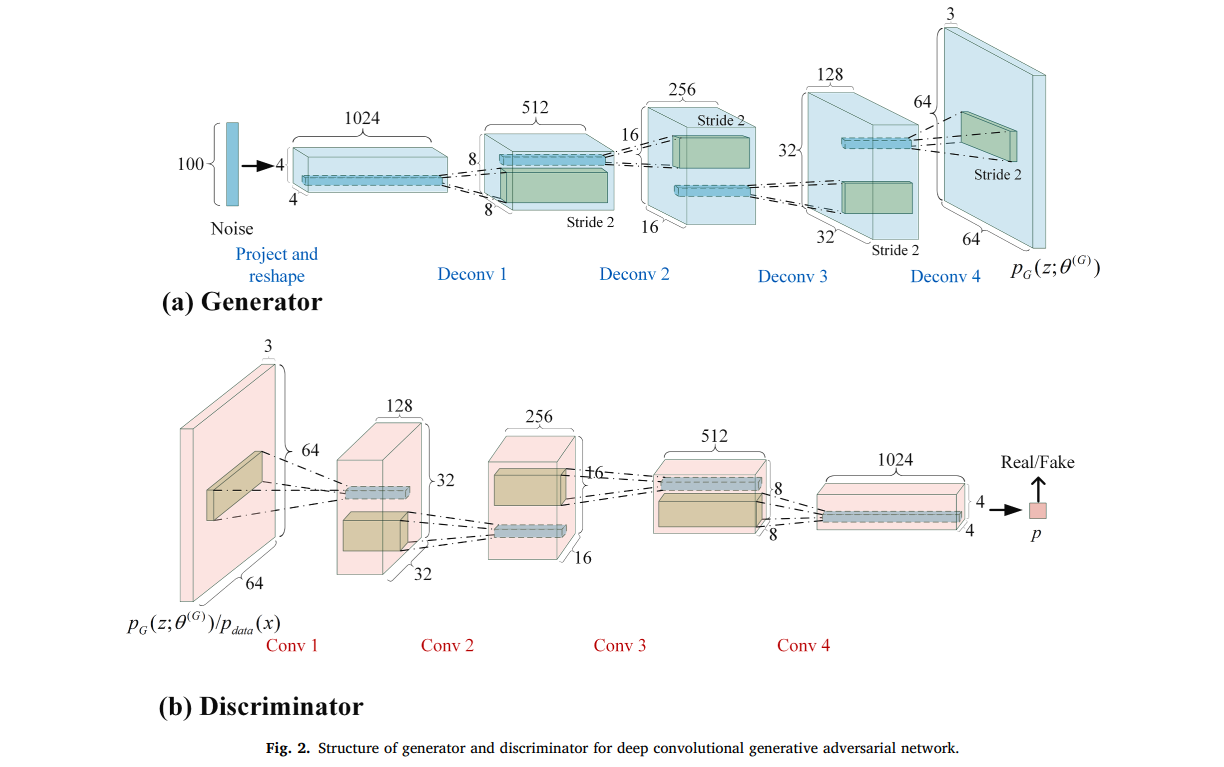
这部分我将用GAN实现一个动画人脸的生成,利用的模型是DCGAN,它在原始GAN模型的基础上,将生成器和判别器的网络结构换成了当时已经十分成熟的卷积神经网络结构,并对卷积神经网络结构进行一定的调整,克服了原始GAN训练不稳定和梯度消失的问题。具体改变有:
- 取消所有的pooling层。生成器中使用fractionally strided convolution代替pooling层,判别器中使用strided convolution代替pooling层。
- 在生成器和判别器中都使用批量标准化
- 去除了全连接层
- 生成器中使用ReLU作为激活函数,最后一层使用tanh激活函数
- 判别器中使用LeakyReLU作为激活函数
DCGAN的网络结构如下图所示:
现在让我们来实现这一部分,首先现在我们需要导入本作业需要的一些包,并设置随机种子的个数(这部分直接复制粘贴就好)
import torch.nn as nn
import os
import glob
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader
from torch.autograd import Variable # 产生随机分布
import matplotlib.pyplot as plt
import random
import torch
import numpy as np
seed = 2022
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True数据预处理
Dataset
需要使用transforms将图片转成以下格式:
- 修改图片尺寸为(64, 64)
- 将数值从[0, 1]映射到[-1, 1]
- 转成tensor格式读入
# Dataset
class CrypkoDataset(Dataset):
def __init__(self, fnames, transform):
self.fnames = fnames
self.transform = transform
def __len__(self):
return len(self.fnames)
def __getitem__(self, idx):
fname = self.fnames[idx]
img = torchvision.io.read_image(fname) # 读取图片
img = self.transform(img) # 对图片进行一定的修改
return img制定transform规则并获取dataset
fnames = glob.glob(os.path.join('./faces', '*'))
# 1. 修改图片尺寸为(64, 64)
# 2. 将数值从 [0, 1] 线性映射到 [-1, 1]
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5),std=(0.5, 0.5, 0.5)),
])
dataset = CrypkoDataset(fnames, transform)展示一组照片
images = [dataset[i] for i in range(16)]
grid_img = torchvision.utils.make_grid(images, nrow=8)
plt.figure(figsize=(20, 20))
plt.imshow(grid_img.permute(1, 2, 0))
由于我们使用了transform将数据的范围变成了[-1, 1],因此我们需要将其转换为[0, 1],才能展示出正确的图片
images = [(dataset[i] + 1) / 2 for i in range(16)]
grid_img = torchvision.utils.make_grid(images, nrow=8)
plt.figure(figsize=(20, 20))
plt.imshow(grid_img.permute(1, 2, 0))
Model
现在实现模型的部分,这一部分也可以自行修改
# 模型参数初始化
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
m.weight.data.normal_(0.0, 0.02) # 均值为0,标准差为0.02的正态分布
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0) # 均值为1,标准差为0.02的正态分布
# 生成器
class Generator(nn.Module):
def __init__(self, in_dim):
super(Generator, self).__init__()
def dconv_bn_relu(in_dim, out_dim):
return nn.Sequential(
nn.ConvTranspose2d(in_dim, out_dim, kernel_size=5, stride=2, padding=2, output_padding=1, bias=False),
nn.BatchNorm2d(out_dim),
nn.ReLU(),
)
self.l1 = nn.Sequential(
nn.Linear(in_dim, 512 * 4 * 4),
nn.BatchNorm1d(512 * 4 * 4),
nn.ReLU(),
)
self.l2_5 = nn.Sequential(
dconv_bn_relu(512, 256),
dconv_bn_relu(256, 128),
dconv_bn_relu(128, 64),
nn.ConvTranspose2d(64, 3, kernel_size=5, stride=2, padding=2, output_padding=1),
nn.Tanh(),
)
self.apply(weights_init)
def forward(self, x):
y = self.l1(x)
y = y.view(y.size(0), -1, 4, 4)
y = self.l2_5(y)
return y
# 判别器
class Discriminator(nn.Module):
def __init__(self, in_dim):
super(Discriminator, self).__init__()
def conv_bn_lrelu(in_dim, out_dim):
return nn.Sequential(
nn.Conv2d(in_dim, out_dim, 5, 2, 2),
nn.BatchNorm2d(out_dim),
nn.LeakyReLU(0.2),
)
self.ls = nn.Sequential(
nn.Conv2d(in_dim, 64, 5, 2, 2), nn.LeakyReLU(0.2),
conv_bn_lrelu(64, 128),
conv_bn_lrelu(128, 256),
conv_bn_lrelu(256, 512),
nn.Conv2d(512, 1, 4),
nn.Sigmoid(),
)
self.apply(weights_init)
def forward(self, x):
y = self.ls(x)
y = y.view(-1)
return y 设置超参数
这部分可以进行调节
batch_size = 64
z_dim = 100
z_sample = Variable(torch.randn(100, z_dim)).cuda() # 随机生成100个样本,用于检测模型的训练结果
lr = 1e-4
n_epoch = 10开始训练
准备好dataloader,model,loss criterion,optimizer
# 生成一个文件目录,用于保存模型结果
save_dir = './logs'
os.makedirs(save_dir, exist_ok=True)
# dataloader
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# model
G = Generator(in_dim=z_dim).cuda()
D = Discriminator(in_dim=3).cuda()
G.train()
D.train()
# loss criterion
criterion = nn.BCELoss()
# optimizer
opt_G = torch.optim.Adam(G.parameters(), lr=lr, betas=(0.5, 0.999))
opt_D = torch.optim.Adam(D.parameters(), lr=lr, betas=(0.5, 0.999))Training
for epoch in range(n_epoch):
for i, data in enumerate(dataloader):
imgs = data.cuda()
bs = imgs.size(0)
"""训练D"""
z = Variable(torch.randn(bs, z_dim)).cuda()
g_imgs = G(z) # 生成的概率分布
r_imgs = Variable(imgs).cuda() # 真实数据的概率分布
# 对两种数据打标签,真实为1,生成的为0
g_label = torch.zeros((bs)).cuda()
r_label = torch.ones((bs)).cuda()
# 两种数据经过判别器
g_logits = D(g_imgs)
r_logits = D(r_imgs)
# 计算D的loss
g_loss = criterion(g_logits, g_label)
r_loss = criterion(r_logits, r_label)
loss_D = (g_loss + r_loss) / 2
# 后向传播更新D的模型参数
D.zero_grad()
loss_D.backward()
opt_D.step()
"""训练G"""
z = Variable(torch.randn(bs, z_dim)).cuda()
g_imgs = G(z)
# 生成数据经过判别器
g_logits = D(g_imgs)
# 计算loss
loss_G = criterion(g_logits, r_label) # 生成器的目的是生成和真实数据一样的分布,因此用的是r_label
# 后向传播更新G的模型参数
G.zero_grad()
loss_G.backward()
opt_G.step()
# 打印当前模型训练的状态
print(f'\rEpoch [{epoch+1}/{n_epoch}] {i+1}/{len(dataloader)} Loss_D: {loss_D.item():.4f} Loss_G: {loss_G.item():.4f}', end='')
# 每进行一次epoch,生成一组图片,用于评估模型训练的情况
G.eval()
g_imgs_sample = (G(z_sample).data + 1) / 2
filename = os.path.join(save_dir, f'Epoch_{epoch + 1:03d}.jpg')
torchvision.utils.save_image(g_imgs_sample, filename, nrow=10)
print(f' | save samples to {filename}')
# 展示生成的图片
grid_img = torchvision.utils.make_grid(g_imgs_sample.cpu(), nrow=10)
plt.figure(figsize=(10, 10))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()
# 将G转换成训练模型
G.train()
# 模型保存
torch.save(G.state_dict(), os.path.join(save_dir, f'dcgan_g.pth'))
torch.save(D.state_dict(), os.path.join(save_dir, f'dcgan_d.pth')) Epoch [1/10] 1115/1115 Loss_D: 0.5579 Loss_G: 2.0209 | save samples to ./logs\Epoch_001.jpg

Epoch [2/10] 1115/1115 Loss_D: 0.2129 Loss_G: 6.2952 | save samples to ./logs\Epoch_002.jpg
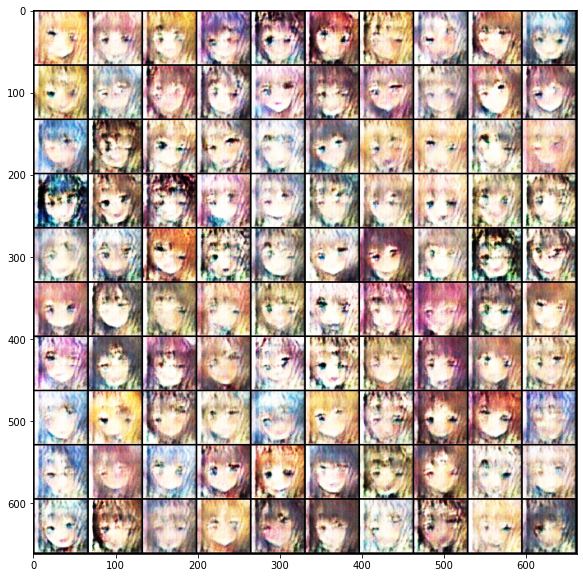
Epoch [3/10] 1115/1115 Loss_D: 0.2469 Loss_G: 2.8889 | save samples to ./logs\Epoch_003.jpg

Epoch [4/10] 1115/1115 Loss_D: 0.3291 Loss_G: 3.8916 | save samples to ./logs\Epoch_004.jpg

Epoch [5/10] 1115/1115 Loss_D: 0.2093 Loss_G: 3.2604 | save samples to ./logs\Epoch_005.jpg

Epoch [6/10] 1115/1115 Loss_D: 0.1691 Loss_G: 3.0890 | save samples to ./logs\Epoch_006.jpg

Epoch [7/10] 1115/1115 Loss_D: 0.1185 Loss_G: 3.0753 | save samples to ./logs\Epoch_007.jpg

Epoch [8/10] 1115/1115 Loss_D: 0.1162 Loss_G: 3.1938 | save samples to ./logs\Epoch_008.jpg

Epoch [9/10] 1115/1115 Loss_D: 0.1183 Loss_G: 4.2176 | save samples to ./logs\Epoch_009.jpg

Epoch [10/10] 1115/1115 Loss_D: 0.1022 Loss_G: 2.4000 | save samples to ./logs\Epoch_010.jpg

结果展示
现在我们就可以利用我们训练好的Generator来随机生成图片
# 模型加载
G = Generator(z_dim)
G.load_state_dict(torch.load(os.path.join(save_dir,'dcgan_g.pth')))
G.eval()
G.cuda()
n_output = 20
z_sample = Variable(torch.randn(n_output, z_dim)).cuda()
imgs_sample = (G(z_sample).data + 1) / 2.0
filename = os.path.join(save_dir, f'result.jpg')
torchvision.utils.save_image(imgs_sample, filename, nrow=10)
# show image
grid_img = torchvision.utils.make_grid(imgs_sample.cpu(), nrow=10)
plt.figure(figsize=(10,10))
plt.imshow(grid_img.permute(1, 2, 0))
虽然图中的动画人物看起来很怪,但也有几分和动画人物相似,并且有的已经非常像了。这里我只把n_epoch设置为10,如果将n_epoch设置大点,我想结果会好点。



